2024-Q4-AI-LV-Business 4. Mākslīgie neironu tīkli, klasifikācijas un regresijas modeļi
4.1. Video / Materiāli (8 Jan 2024, 18:00)
Zoom (jānospiež ieraksts sākumā, pēc tam tiks ielikts youtube unlisted mode): https://us06web.zoom.us/j/81532941877?pwd=L1IgtKhCzcsLfxa5OKjB4N6ChulOab.1 Meeting ID: 815 3294 1877 Passcode: 388048
Materials: https://www.geeksforgeeks.org/neural-networks-a-beginners-guide/ https://www.youtube.com/@3blue1brown

Rīki
Altair AI studio (var dabūt bezmaksas versiju) air RapidMiner AI studio, https://docs.rapidminer.com/latest/studio/installation/index.html#from-rapidminer
Pieeja H2O sistēmai:

xxxxxxxxxx31URL: https://h2o.asya.ai2u: h2o3p: venta2024
Saturs
Iepriekšējā cikla lekcijas Video: https://youtube.com/live/wQ9Q5zLFkEs?feature=share
Whiteboard: https://whiteboard.fi/f293cc85-489b-4c57-a207-ec2d6a5b96f3
Apskatīties dažus piemērus no iepriekšējā mājasdarba, lai motivētu studentus veikt mājasdarbus
Izstāsīt analoģiju par dabīgajiem neironu tīkliem un perceprtonu. Vēsturi pastāstīt. aktivizācijas funkcijas pastāstīt. Pastāstīt arī , ka priekš Deep Learning Neural networks kā minimums vajag 10-50k paraugus, ja mazāk dati ieteicams lietot iepriekšejās lekcijās apskatītās metodes.




Pastāstīt kā mākslīgie neironu tīkli izpildās matemātiski, mazliet pastāstīt par to kas īsti ir matematemātiskajās funkcijās. Ka rotācijas + translācija īstenībā ir tas pats vienādojums, kuru izmanto GPU, lai zīmētu trijstūrus datorrspēlēs, un šeit tas noder arī priekš mākslīgajiem neirnu tīkliem. Kursa dalībnieki nav matemātiķi, jādod tikai ieskats.



Parādīt http://playground.tensorflow.org un pastāstīt intuitīvi kāpēc nepietiek ar Linear seperation, kāpēc vajag nonlinearities. Izstāstīt par visiem hiper-parametriem: Learning rate, layer count, Activation





Izstāstīt par datu sagatavošanu, ka vajag izprast datus, Normalizēt (feature scaling), cik iespējams augmentēt. Normalize data, split data into train, test and validation (80% vs 20%) or (70% vs 20% vs 10%). K-fold split. Data augmentation, each model has its limitations (if you have just 1000 samples, with augmentation you can get 10000-100000)




Pastāstīt par tipiskajām arhitektūrām - DNN, CNN, ResNet, Transformer - kam kura ir paredzēta, bet ne parāk dziļi. Primāri jāliek viņiem saprast, ka tas ir matemātisko funkciju grafs, kur katra kastīte ir funkcija.

Pastāstīt par Classification, Regression. Iedot piemērus no interneta veikala - user activity prediction, price prediction, etc., jo dalībnieki būs biznesa studenti.


Pastāstīt intuitīvi kā strādā backpropogation, atpakaļizplatīšanās algoritms. Pastāstīt, ka Geofrey Hinton par šo algoritumu 2024. gadā dabūja nobela prēmiju Fizikā. Pastāstīt, kas ir Epoha. Pastāstīt, ka gradients no kļūdas funkcijas strādā kā dabā zibens vai kā ūdens tek, uzdot gotcha jautājumu par loss function līkni. Pastāstīt arī par Stohastiskā kalnā kāpēja algoritmu SGD. Noteikti parādīt piemēru ar Class Activation Map bildi par PascalVOC dataset, kur AI iemācās atpazīt zirgu pēc paraksta un vieglākā risinājuma nevis pēc cilvēkam saprotams loģikas.

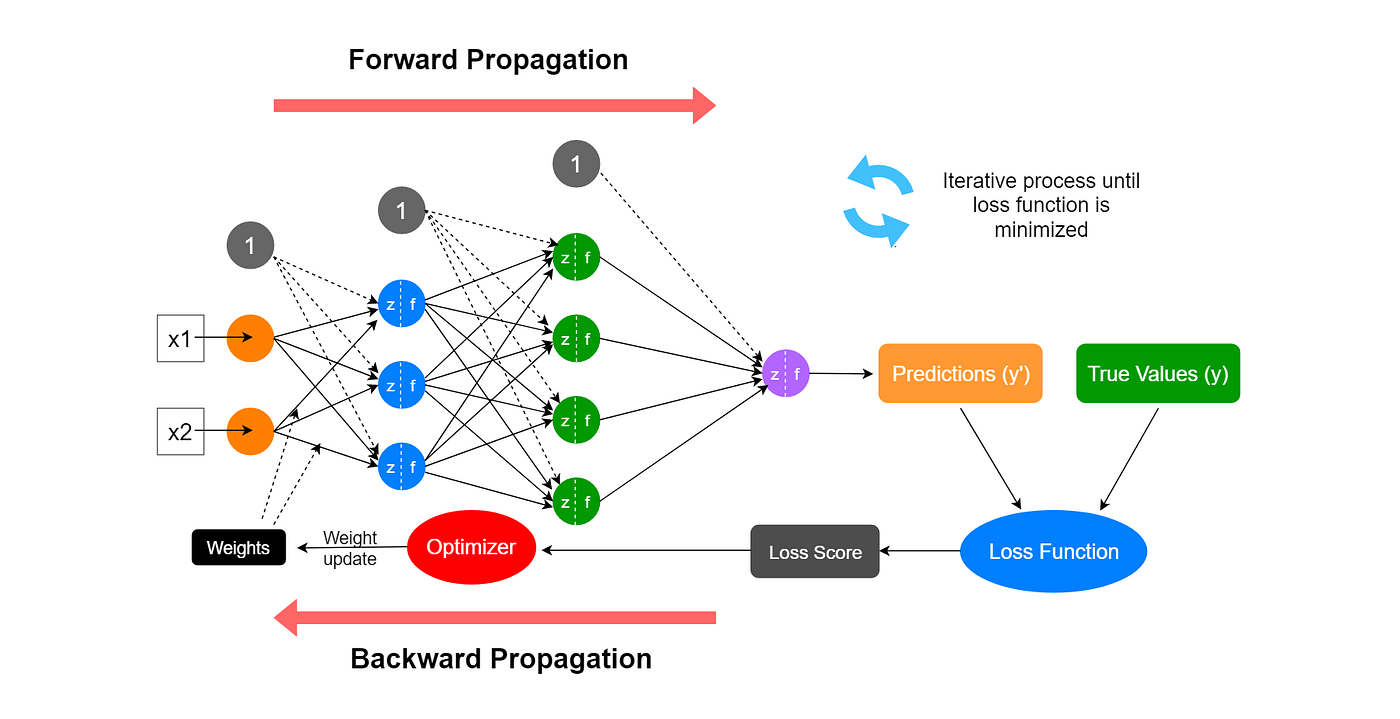












Izstāsīt visu training ciklu. Pastāstīt par to kā rēķina accuracy, confusion matrix, F1 score, bet tikai informatīvi. Izstāstīt par Overfitting (pārapmācīšanos), Underfitting (zemapmācīšanos) un normālu apmācīšanos




xxxxxxxxxx221Steps:21. Data31. Understand data42. Normalize data, split data into train, test and validation53. Data augmentation, each model has its limitations62. Model71. Deep learning model architecture (boxes)82. Hyper-parameters93. Loss function:101. MSE, MAE - Regression, scalar value112. CCE, BCE - Classification124. Additional metrics:131. R2, NRMSE - Regression142. Acc., F1 - Classification155. Training cycle161. Epoch - use whole dataset once171. Training stage - Change model weights using Backpropagation, SGD182. Test stage - predict results without training193. Store metrics in plot204. Stop before overfitting216. Validation check227. Save model and use in production to predict results without training
Parādīt kā sastādīt H2O Deep learning modeli. Augšupielādēt CSV failu. Noprocesēt datu kolonu tipus. Sadalīt Train un test kopās. Atzīmēt ignored kolonas modelim, izskaidrot kāpēc! Sastādīt arhitektūru un izstāstīt kā tā veidojas. Izvēlēties adekvātu loss funckiju






Pastāstīt un parādīt Variable importances, par to, ka modeļi nav black-boxes, bet tajos var “ieskatīties” izmantojot metodes kā, piemēram, SHAP LIME GRADCAM ELI5

Parādīt kā šo pašu var realizēt ar Altair AI studio

4.2. Klientu novērtējuma prognozēšana
Izmantojot doto datu kopu, apmāciet modeli, izmantojot H2O vai Altair AI studiju, lai prognozētu "Vērtējumu", kas norāda uz apmierinātības novērtējuma prognozi.
http://share.yellowrobot.xyz/quick/2023-10-12-931888F3-5E95-4F53-9D22-85246F6C291F.zip
Iesniedziet modeļa kļūdas funkcijas līkņu un prognozēto rezultātu ekrānuzņēmumus. Tāpat izveidojiet un iesniedziet pašizveidotu CSV failu, kuram tika iegūta prognoze.
4.3. Mājasdarbs - Nekustamā īpašuma cenas prognozēšana
Izmantojot doto datu kopu, apmāci modeli, izmantojot H2O vai Altair AI studiju, lai prognozētu "Y mājas cenas vienības teritorijā" no citiem parametriem, kurus tev piedāvā izvēlēties.
http://share.yellowrobot.xyz/quick/2023-10-12-347B9B69-6759-4241-A678-C22AD5487D3C.zip
Iesniedz modeļa kļūdas funkcijas līkņu un prognozēto rezultātu ekrānuzņēmumus. Izveido un iesniedz pašveidotu CSV failu, kas satur prognozes.

