2024-12-06 AI Meeting
Mārcis
Report: https://www.notion.so/evalds/2024-12-06-ddd8ce6a83c9427a930b6309b8776faf?pvs=4
Done:
STT fixes ar
loudness normalization
compression
LH/HP
GPT tīrīšana
baigi -> ļoti
Speech Recognition (STT). Implemented Whisper loudness normalization with compression and LP/HP filtering, with waveform comparisons completed
Gramatiņs. Added 130k new samples from scraped forum user comments and cleaned existing data
Implemented worker-coordinator communication using ZeroMQ
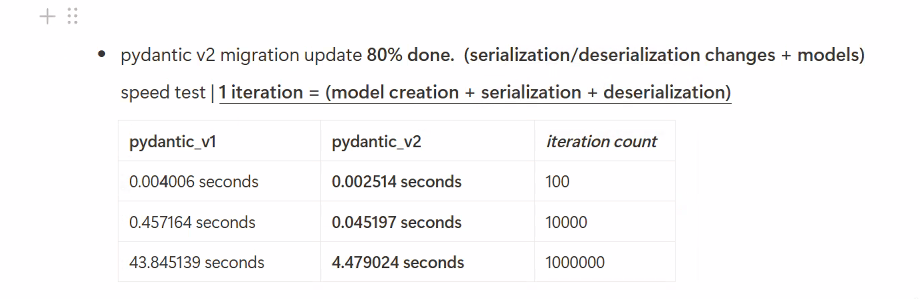
Completed 80% of Pydantic v2 migration with significant performance improvements - up to 10x faster processing Set up API development environment on asya4 with STT worker configuration
TODO:
API
Atrast, kur ir nākmais bottleneck, nepieciešams workeros sadalīt CPU un GPU daļu 2 dažādos multiprocess (datu apmaiņa var būt caur multiprocess queue) tā, lai nākmais batch vienmēr būtu gatavs. Līdzīgi kā Pytorch apmācībā Dataloader ar num_workers un multiprocessing.
ParkExpert (support)
👥 Sarunāt zvanu ar Heniņu un Artūru Uldi un palīdzēt izstāstīt kā pārveidot workers tā, lai tie strādātu tāpat kā main API. Viņiem vajag līdzīgu optimization kā main API. Tas, kas ir totāli nepareizi ir, ka katrai kamerai ir savs worker. Nav arī nekāda jēga izmantot shared memory modeli, jo izsaukt varēs tāpat itkai viens forward parallēli, jāpanāk, ka pirms katra call ir jau gatavs batches nevis veic CPU tasks tajā pašā multiprocess.
STT
Real-time STT uzlikt loudness normalization.
Apmācīt ar jaunajiem datiem Real-time STT.
Saņēmām sūdzības par STT kvalitāti salīdzinot ar Tildi, lūdzu apskaties, kā varam uzlabot šo situāciju" https://share.yellowrobot.xyz/quick/2024-12-7-86BF62FD-C390-497F-9F91-F5860FB8E3B5.zip
Saīsinājumus implementēt kā Assitentis prasīja nevis kilograms -> kg, utt
Kā varam uzlabot skaitļu atpazīšanu?
Grāmatiņš
Nevācam caur Google Translate no Eldigen produkcijā datus. Ja nepieciešams tad caur GPT vai Google Translate paši varam Source LV pārtulkot un izmantot apmācībā
Pārliecināties, ka hashtags, emojis saglabājas. šobrīd emoji teksti nomainās sk zemāk screenshot
LLM
Izpētīt labāko quantized Mistral vai LLama model, kuru varētu uzlikt uz RTX4090 un izpētīt ātrumu un precizitāti summary ģenerēšanā (caur translation). Ja ir kāds mazāks modelis, kurš spēj English summary caur prompt engeneering, tad izmēģināt to, lai pēc iespējas mazāk izmantojam RTX.
Intent zero shot classification modeli izpētīt, vai varētu būt lietderīgs.
Sentiment zero shot classification modeli izpētīt, vai varētu būt lietderīgs.

Krišs
Report: https://www.notion.so/evalds/Report-0c116eb887b54cdb9ebf79b355046d9c?pvs=4
Done:
Robocall Update
Completed Polish language support and Google STT API integration
Frontend development has been initiated
Text to Speech Progress
English VITS model training is in evaluation phase
Initial training results look promising without phoneme usage
Dataset enhancement in progress with additional Dina voice content
Working on resolving VITS 2 training script issues
TODO:
Pirmais UX, kurā var konfigurēt robocall. Flask struktūras piemēru ņemt no Eldigen (tikai lūdzu neizmantojam SQLAlchemy, esam sapratuši, ka manual postgreSQL SQL ir daudz ātrāks. DB pusi skatīties no main API code).
👥 Dokumentēt, publicēt un padalīties ar Weights and Biases library Artūram Uldim, Gustavam un Mārcim. Artūram īpaši parādi, kā bildes pievienot.
Implement real-time speech-to-text training with numbers
Arturs Uldis
Report: https://www.notion.so/evalds/2024-12-06-Art-rs-Report-cad681891ac04e5fbf895e4dfd75739f?pvs=4
Done:
Zippyvision
Veikti 2 Unet modeļa testi uz lielo datu kopu
Nepieciešams risinājums, kas var izmantot nemarkētos datus, bet autoencoder pieeja ir problemātiska segmentācijai
DINO nav optimāla izvēle, jo tas fokusējas uz attēla iezīmēm, kas šim gadījumam nav būtiskas
Pašlaik Miza 84% IoU, bet Zars 65% IoU
FaradAI
Objektu segmentācija gandrīz pabeigta visiem video, bet kvalitāte nav apmierinoša
LLM2CLIP tiek ieviests HPC, plānots izmantot satura un attēla tipa analīzei
Parkexpert
Kustības noteikšana izrādījusies neefektīva, jo kamerās ir pastāvīga aktivitāte
Nepieciešams uzlabot car_detection worker veiktspēju ar multiprocessing un shared_memory modeļa palīdzību
Pastāv bažas par sistēmas veiktspēju pie liela kameru skaita
TODO:
ZippyVision
Salabot weighted loss funkciju, balstoties uz pixel sum pa klasēm, lai zaru pixel būtu ievērojami lielāks loss.
Pārbaudīt grid search ar FocalLossCCE (gamma = 2), Tversky loss funkcijām. 3. Uzlabot augmentācijas - ierobežojumi, kurus viņi teica, nevajag pārāk rotēt, bet filip v, fliph, - color defeki un zīmējumi. Dokumentēt kā tu vizuāli augmentē kameras defektus - tos sarkanos pleķus
Grayscale kanāls klāt visam un labākas architectures - DeepLabV3 ar pre-trained (jāsakrīt dokumentācijas input normalizācijas) + citas archs
Iegūt pirmo kopējo Zaru, Mizu modeli, validēt apmācību laikā uz ozola kopas 20% (pārliecināties, ka tie nav iekļauti apmācībā). Validēt arī uz datu kopu kādai, kas nebija labākā iepriekšējos gatavajos modeļos (pārliecināties, ka tie nav iekļauti apmācībā).
Apmācības laikā iekļaut pēdējā test batch bildes weights and biases.
Pārbaudīt IoU rezultātus jau ar iepriekš apmācītiem modeļiem, lai varam pierādīt uzlabojumus
Sagatavot atskaiti ar vizualizācijām un grafikiem.
FaradAI
Evaldam prezentācija datu kopai 3dien no rīta, Evalds pats gatavos atskaiti, bet vajag datus
Pēc iespējasi vairāk paraugus noprocēsēt un pārvietot uz ventspils-1 faradai
Palaist LLM2CLIP uz paraugiem, pēc iespējas vairāk ievākt datus
Vēlāk pieslēgsim manual labeller
ParkExpert
Sarunāt zvanu ar Mārci par ParkExpert workeru pārkodēšanu. Jāievieš batching, NEIZMANTOT shared memory modeli. Katram worker jābūt 2 multiprocess - viens CPU, viens GPU. CPU uzdevums ir sagatavot batches jau uz priekšu, GPU uzdevums ir forward, dati tiek nodoti caur multiprocess queue. Worker nedrīkst būt piesaistīts kādam konkrētam kamerai, jāvar pievienot vairāk workers, kas varēs strādāt paralēli. Jābūt coordinator, kas izda workeram darbu.
Motion detection var uzlabot ar OpenCV OpticalFlow
Gustavs
Done:
Datu kopas un trūkstošie dati
WT_DB2 kopā pilnībā trūkst TCC un ICP kolonnas
WT_DB3 kopā ir 20% iztrūkstošu vērtību
Visās kopās ar LabeledIntervalID kolonnu tā ir pilnībā tukša 2.Parametru neatbilstības
Dokumentācijā minētie parametri TTC un IIC nav atrasti kolonnās, iespējams, tie ir līdzvērtīgi TCC un ICC 3.Datu struktūra
Analizētas vairākas datu kopas: WT_DB1, WT_DB2, WT_DB3, un vairāki Bactosense un sensoru mērījumi no WT_P2, WT_P3, un WT_P4
Katrai kopai ir individuāla laika līnija un laika soļi, kas dokumentēti ar grafiskiem attēliem
WT_P2 defekts TOC sensoru rādījumā

TODO:
Waterson
Izveidot skriptu, kas var salāgot WT un Bactosense datus kopā pa definētu intervālu - testējam 30, 90, 360 min (iespējams vēlāk veidosim modeli, kur apvienosim visus, šos intervālus un teiksim, ka modelis darbojas jebkurā intervālā starp 30 un 360 min)
Savarīgi! Nepareizi modelēt vērtību Waterson average no 2 punktiem, jāmodelē viss range kurā lēnām notiek bactosense aktivitāte.
WT_P3, Waterson sensoru rādījumiem apstrādāt pēkšņus lēcienus. mums tos vajag atpazīt un sadalīt datu kopu, lai modelis nemācās modelēt šīs situācijas. (Zemāk bilde)
WT_P3 ir lieli caurumi vairāku dienu pediodos, sadalīt datu kopu tā, lai ir contigous dati.
WT_P2 labāk neizmantot, jo ir neizskatās ticami dati.
Izveidot pirmo XGBoost modeli:
Ievade: Waterson
Izvade: TOC, TCC, ICC kā deltu klases (-100%+, -50%+, 0%, +50%, +100%) . Regression nebūs labi ar XGBoost
Salīdzināt arī ar CATBoost https://catboost.ai/docs/en/concepts/python-reference_catboostclassifier
Waterson iesaka modelēt arī HNAC, LNAC, HNAP. Par Bactosense merijumiem, papildus esošiem ICC, TCC, DCC, mēs iesakam analīzē ņemt vērā arī HNAC, LNAC, HNAP rādījumus, lai palīdzētu novērtēt izmaiņas. Šiem parametriem vajadzētu būtiski palīdzēt novērtēt izmaiņu dinamikas. " HNAC: Concentration of bacteria with a high nucleic acid content. LNAC: Concentration of bacteria with a low nucleic acid content.HNAP: Percentage of bacteria with a high nucleic acid content." https://www.bnovate.com/bactosense-cartridge. Pielikumā arī screenshot no Bactosense mājaslapas.
FaradAI
Sagatavot atskaiti, kuru varam rādīt konferences laikā
Reinis
Report: https://www.notion.so/evalds/2024-12-06-Report-039dcdac48fa414697ad5914cb7c0176?pvs=4
Done:
Bikus Project Updates
Pirmais plāns, kas jādara
Eldigen Project Updates
Completed BM25 implementation with several key improvements:
Switched from tsrank to actual BM25 scoring
Updated mining functions with latest filtering
Added new BM25 mining function using nouns and adjectives without stopwords
Corrected fact prioritization sorting
Other Activities
Tele2-related clarifying questions were addressed
TODO:
BIKUS Jābūt atskaitei, kur esam marķējuši primāri NETīROS failus, jo tīrajos būs viegli atpazīt (ja kļūdos saki reini)
50-100 files rindas, kolonas (domāju kā comments iekš excel? uz pirmajām šūnām rindās un kolonās)
Jābūt atskaitei par to cik marķējumi parādās netīrajos failos (nomarķējam pāris arī tīros)
Jāizstrādā prompt based algoritms, kurš rindu vai kolonu pārvērš tekstā un tad salīdzina ar tām, kas ir ielādētas mūsu datu kopā, atrodot piederību nomarķējam konkrēto rindu, kolonu neredzētajā excel (arī varētu kā comment iekš python), lai samazinātu, ka tā nav NP pārmeklēšana pa pāriem varētu lietot word embeddings vai kā citādāk ielādēt sākotnēji līdzīgas rindas kolonas. Alogritmam jāņem vērā blakus esošaās rinas, kolonas un sheet
ielādējam jau datus JSON
Nodot instrukcijas annai kā marķēt datus
Ja nepieciešami degoši updates Eldigen/Tele2, tad palīdzēt
Tiklīdz BIKUS tiks pabeigts mums ir citi savarīgi AI uzdevumi ārpus Eldigen
Adrians
Report: 🔴 Nav report, centīšos nodot SportaCentrs projektu
TODO:
Atrisināt pēc iespējas vairāk problēmas ar Eldigen. Svarīgi palīdzēt pabeigt Document Checker.
Tiklīdz nostabilizēsies Eldigen, plānoti nākamie AI uzdevumi ārpus Eldigen.
Betija
Report: 🔴 Nav report
TODO:
Atrisināt pēc iespējas vairāk problēmas ar Eldigen. Svarīgi palīdzēt pabeigt Document Checker.
🔴 Neaizmirsti par Maģistra darbu, jābūt progresam
Tiklīdz nostabilizēsies Eldigen, plānoti nākamie AI uzdevumi ārpus Eldigen.