2025-03-17 Meeting #3
Github repo: https://github.com/MihailsKostjuks/Bakalaura_darbs_queries
Report: https://docs.google.com/spreadsheets/d/1HCk3xqWTcFWSTmaebXsa-u792wSF_UL-oWHO4t0F61w/edit?gid=0#gid=0
Overleaf:
https://www.overleaf.com/project/67c05089b5996c6526cea098
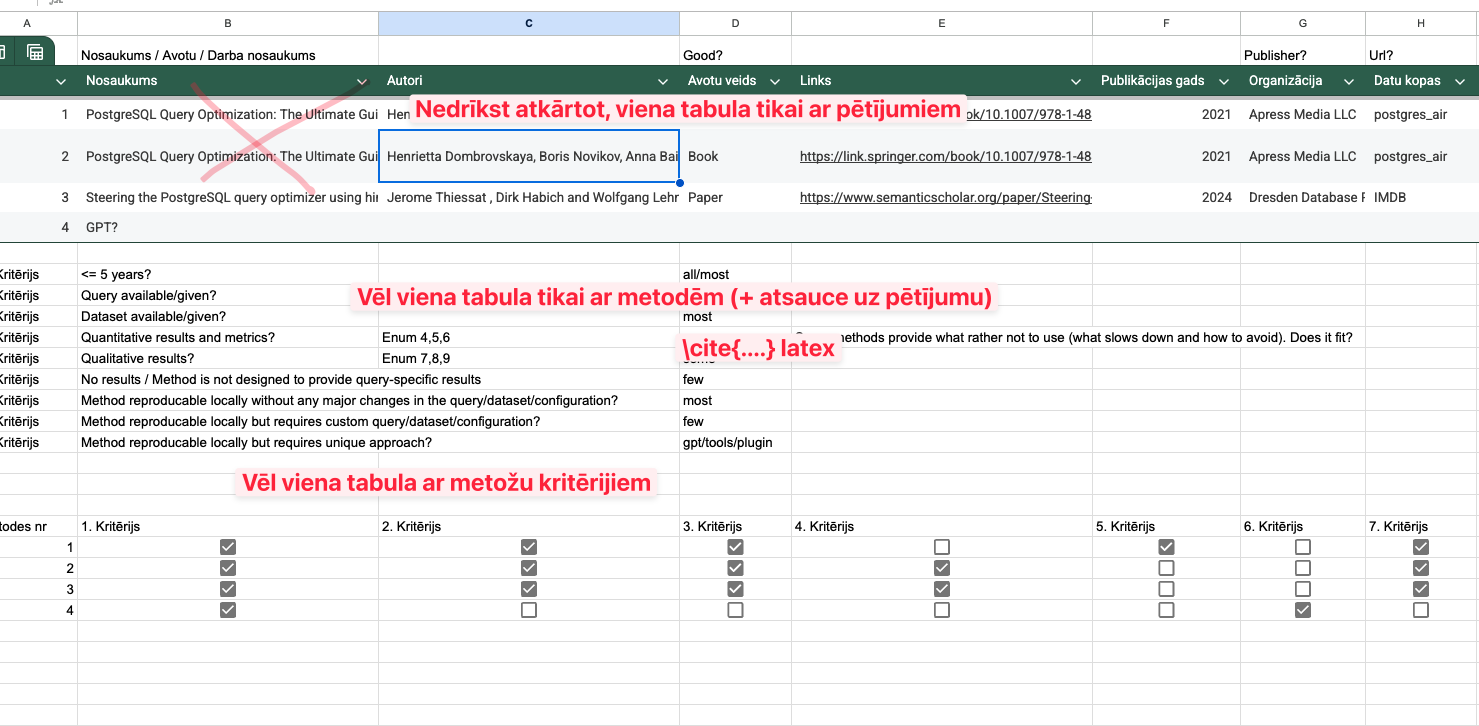
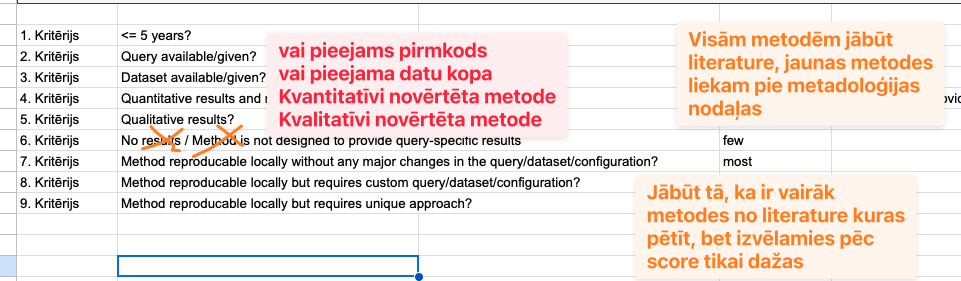
Vēl kritēriji:
Is dataset available?
Is not dataset specific? (works only on that dataset)
Is based on query?
Is not based on database configuration?
Is generalizable on other databases like MySQL, MSSQL, Oracle?
🔴 Vajag Matricu, kur salikt metodes, kuras savstarpēji testējamas
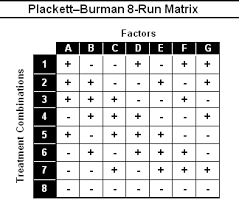
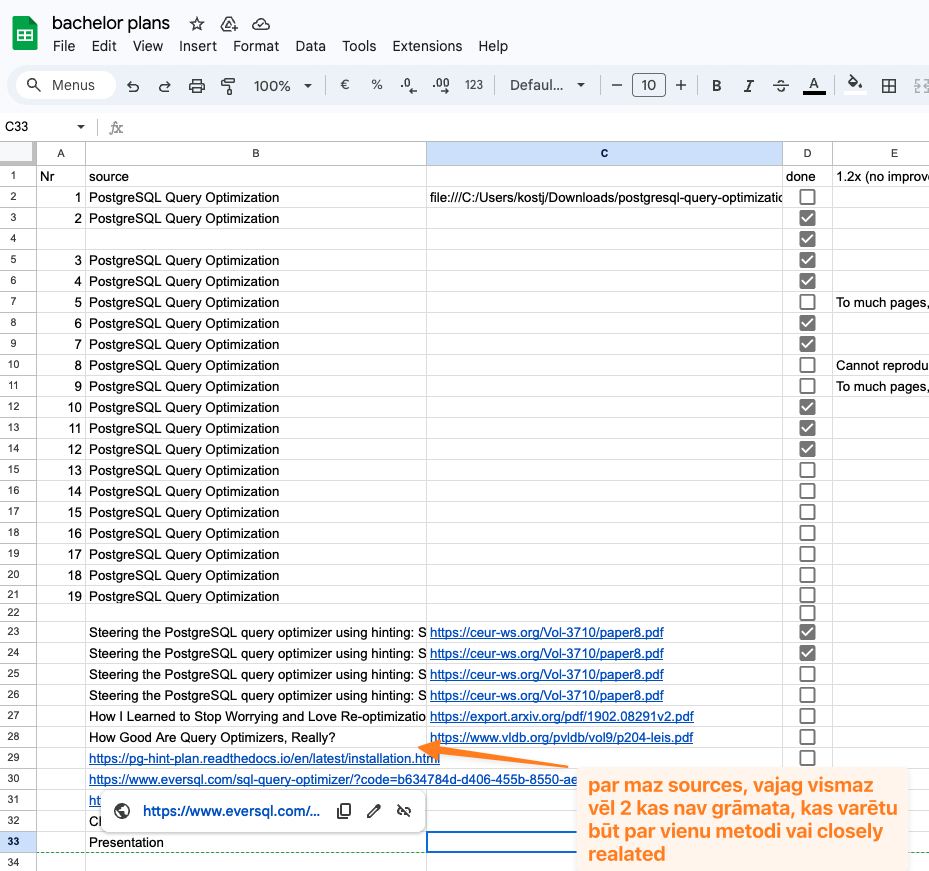
^ Strukturēti pievienot rezultātus kā CSV failus (guthub varēs sekot līdzi saturam) katrai metodei vai datu kopa ^ Var arī pa folderiem
TODO:
SLR nodaļu sākt rakstīt overleaf un salikt 3 tabulas kā vienojāmies
Noteikt cik reizes eksperimentus jaatkārto, lai būtu stabili rezultāti - varbūt nemaz nevajag, jo varbūt rezultāti jēgpilni tikai uz pirmo call!
Uztaisīt Python script, kas izpilda SQL, jo mums vajadzēs atkārtot rezultātus, mērīt utt.
Result:
Salīdzinājums pret baseline (SQL bez optimzācijas) procentos, ja vairākas datu kopas tad arī statistical significance between baseline vs method
Šādi jāizskatās rezultātiem tavā darbā
Method Dataset Response time, ms Baseline Airport 22 Method A Airport 22 Baseline IMDB 22 Method A IMDB 22 Satistical significance between Baseline and Method A = TTEST(a:b, c:d)
Method Dataset Response time, ms Baseline Airport a Baseline IMDB b Method A Airport c Method A IMDB d Salīdzinājums starp metodēm uz kādu no uzdevumiem - piem. meklēšana, insert…
Šādi jāizskatās rezultātiem tavā darbā, ja ir vairāki risinājumi
| Method | Dataset | Response time, ms |
|---|---|---|
| Baseline | Airport | 22 |
| Method A | Airport | 22 |
| Method B | Airport | 22 |
| Baseline | IMDB | 22 |
| Method A | IMDB | 22 |
| Method B | IMDB | 22 |