2025-Q1-AI 10. UNet, Semantic Segmentation, Object Detection
11.1. Video / Materiāli (23. aprīlis trešdiena 18:00)
Zoom (Evalds ielaidīs Zoom):
https://zoom.us/j/3167417956?pwd=Q2NoNWp2a3M2Y2hRSHBKZE1Wcml4Zz09
Sagatavošanās materiāli:
Video no pagājušā gada: https://youtube.com/live/VV6Q2KM9zOY?feature=share
Source Code pabeigts: http://share.yellowrobot.xyz/quick/2023-11-16-151E1E92-44FA-47BD-9500-0FA4CA2A6356.zip
YOLO piemērs
https://share.yellowrobot.xyz/quick/2025-4-21-97299DB9-C7F3-4545-9223-290D25B75BAA.zip
Iepriekšējā gada video un jamboard
Video:
Jamboard:
https://jamboard.google.com/d/1BAwk5fRda0dWjI4sDVzIORKLsuqfIIC4niuBJG56_tc/edit?usp=sharing
Saturs
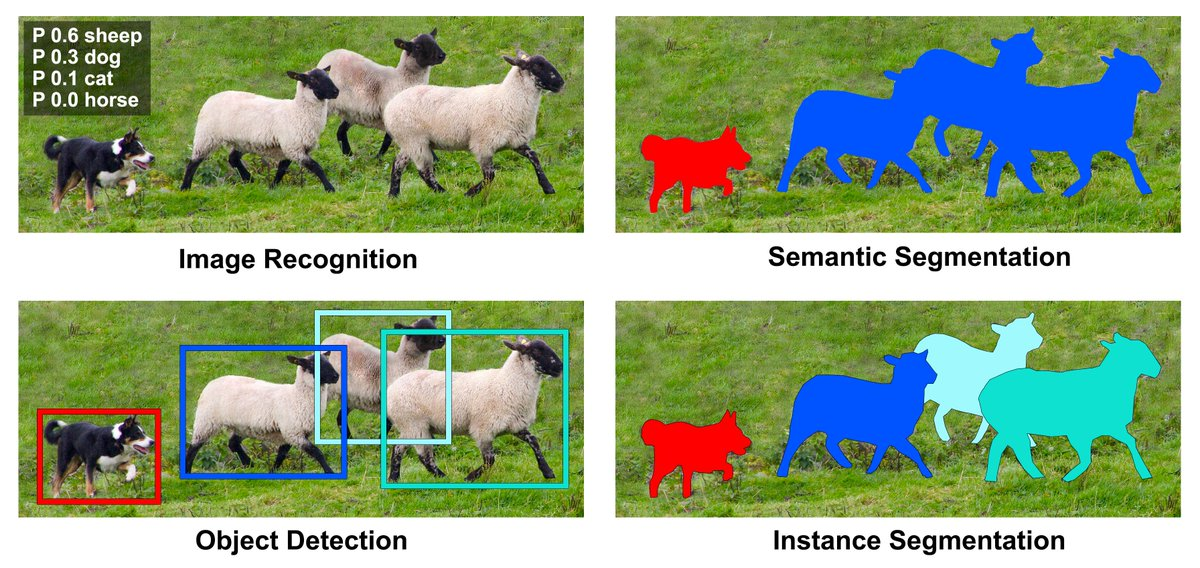
1.Izstāstīt par segmentāciju tipiem
Tipi:
Image recognition / classification ar slīdošo logu
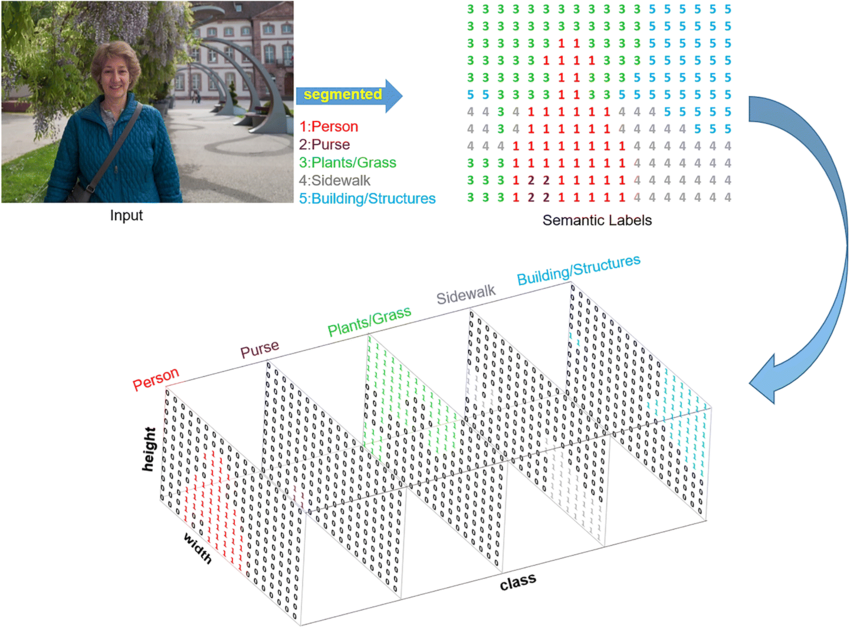
Semantic segmentation (FCN, DeepLab, UNet)
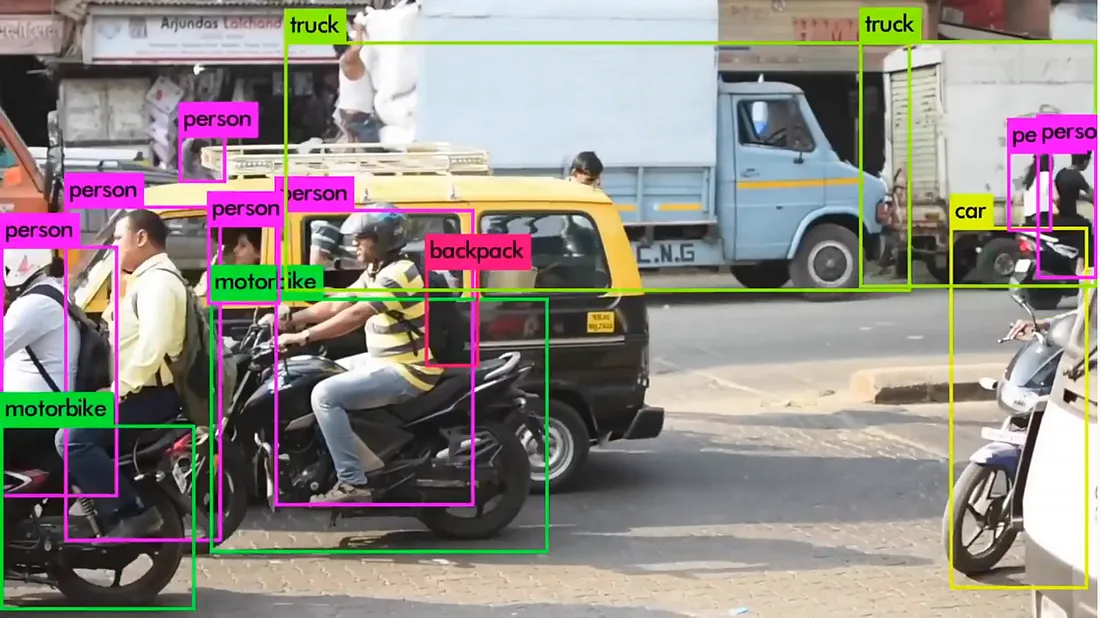
Object Detection (YOLO)
Instance Segmentation (MaskRCNN)
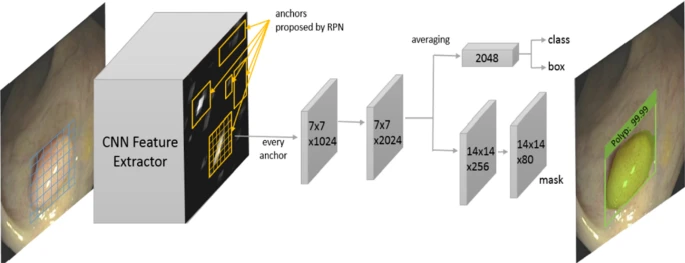
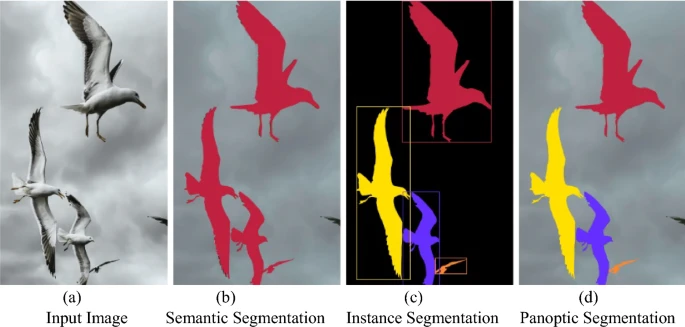
Panatopic segmentation (MaskFormer, PQ metric) https://github.com/sithu31296/panoptic-segmentation
Panoptic segmentation offers key advantages over instance segmentation (e.g., Mask R-CNN) by providing complete scene understanding through unified semantic and instance labeling. Here's how it improves upon traditional instance segmentation:
| Feature | Panoptic Segmentation | Instance Segmentation (Mask R-CNN) |
|---|---|---|
| Scope | Labels every pixel | Focuses only on countable objects |
| Output | Combines semantic + instance IDs | Only instance masks + class labels |
| Ambiguity Handling | Resolves overlaps (no conflicts) | Allows overlapping masks |
| "Stuff" Handling | Labels amorphous regions (sky, road) | Ignores non-object regions |
| Scene Comprehension | Full context awareness | Partial object-focused understanding |

2.Izstāstīt par metrikām
F1, mAP (10%..100%), AP70 (70% threshold), IoU, PQ, DICE
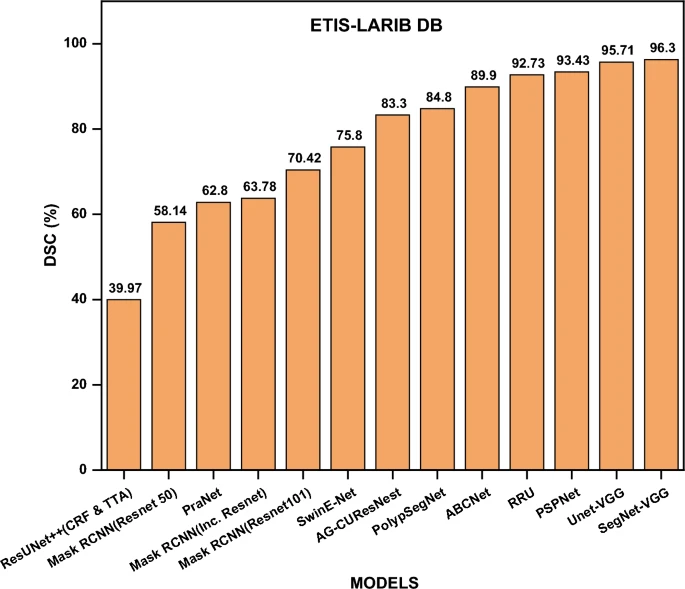
The Dice Coefficient (Jha et al. 2021a; Shamir et al. 2019) is a commonly used statistic for comparing the pixel-by-pixel outcomes of forecasted segmentation with ground truth. It is described as:
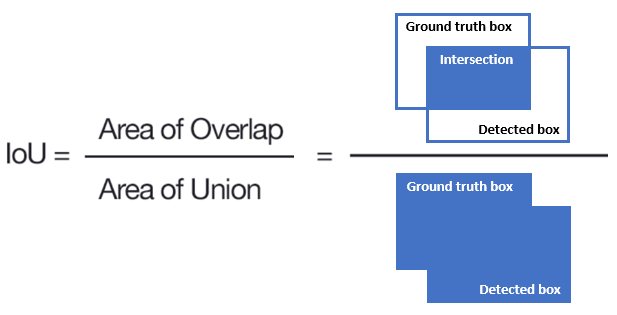
Intersection over union (IoU) There is a popular statistic in polyp segmentation known as intersection-over-union (IoU). The IoU metric measures the number of pixels common between the target and prediction masks divided by the total number of pixels present across both masks. It ranges from 0 to 1 where, a value of zero indicates that there is no overlap, while a value of one indicates flawless overlap. An average of the IoUs of each class is used to calculate the mean IoU of an image for binary segmentation (two classes) or multi-class segmentation. The overlap between two bounding boxes A and B is determined by calculating the ratio of their overlap areas (Rezatofighi et al. 2019).
Pixel accuracy A model’s accuracy parameter measures the model’s performance across a variety of classes. When all classes have equal significance, it is helpful. A prediction accuracy rate is calculated by dividing the number of accurate predictions by the number of predictions overall (Coleman et al. 2019). One alternative method of evaluating image segmentation is to simply report the percentage of pixels in the image that were correctly classified. Each class’s pixel accuracy is commonly reported separately, as well as on a global basis across all classes. A binary mask is used to evaluate the per-class pixel accuracy. True positives are pixels that are accurately predicted to belong to a specific class (according to the target mask), and true negatives are pixels that are accurately identified as not belonging to that class (Ye et al. 2018).
Recall The recall is defined as the percentage of ground truth boundary pixels that were correctly identified by automatic segmentation. A recall is a measure of the proportion of Positive image samples accurately classified as Positive compared to the total number of Positive image samples. It is a measure of how well the model can identify positive samples. The higher the recall, the more positive samples are detected (Aguiar et al. 2019; Xu et al. 2019).
Average precision Average precision is defined as the weighted mean of precisions achieved at each threshold, with the increase in recall as the weight for each threshold:
where Pn and Rn are the precision and recall at the nth threshold. This implementation is not interpolated and is different from computing the area under the precision-recall curve with the trapezoidal rule, which uses linear interpolation and can be too optimistic (Perez-Borrero et al. 2021; De Moura Lima et al. 2023).
Panoptic Quality is the standard metric for panoptic segmentation, a task that unifies
pixel‑level semantic segmentation (“stuff” classes such as sky, road, grass) and
object‑level instance segmentation / detection (“thing” classes such as car, person, dog).
The metric was introduced by Kirillov et al., CVPR 2019, “Panoptic Segmentation.”

https://link.springer.com/article/10.1007/s10462-023-10621-1
https://www.picsellia.com/post/coco-evaluation-metrics-explained
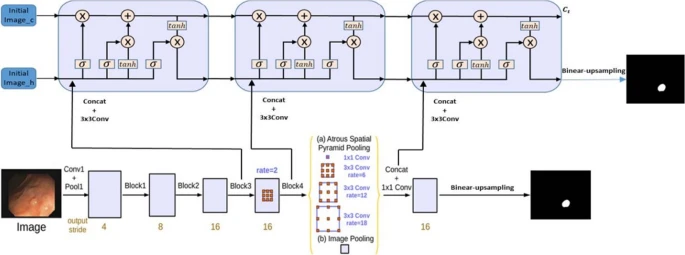
3.Izstāstīt par Semantic Segmentation / UNet
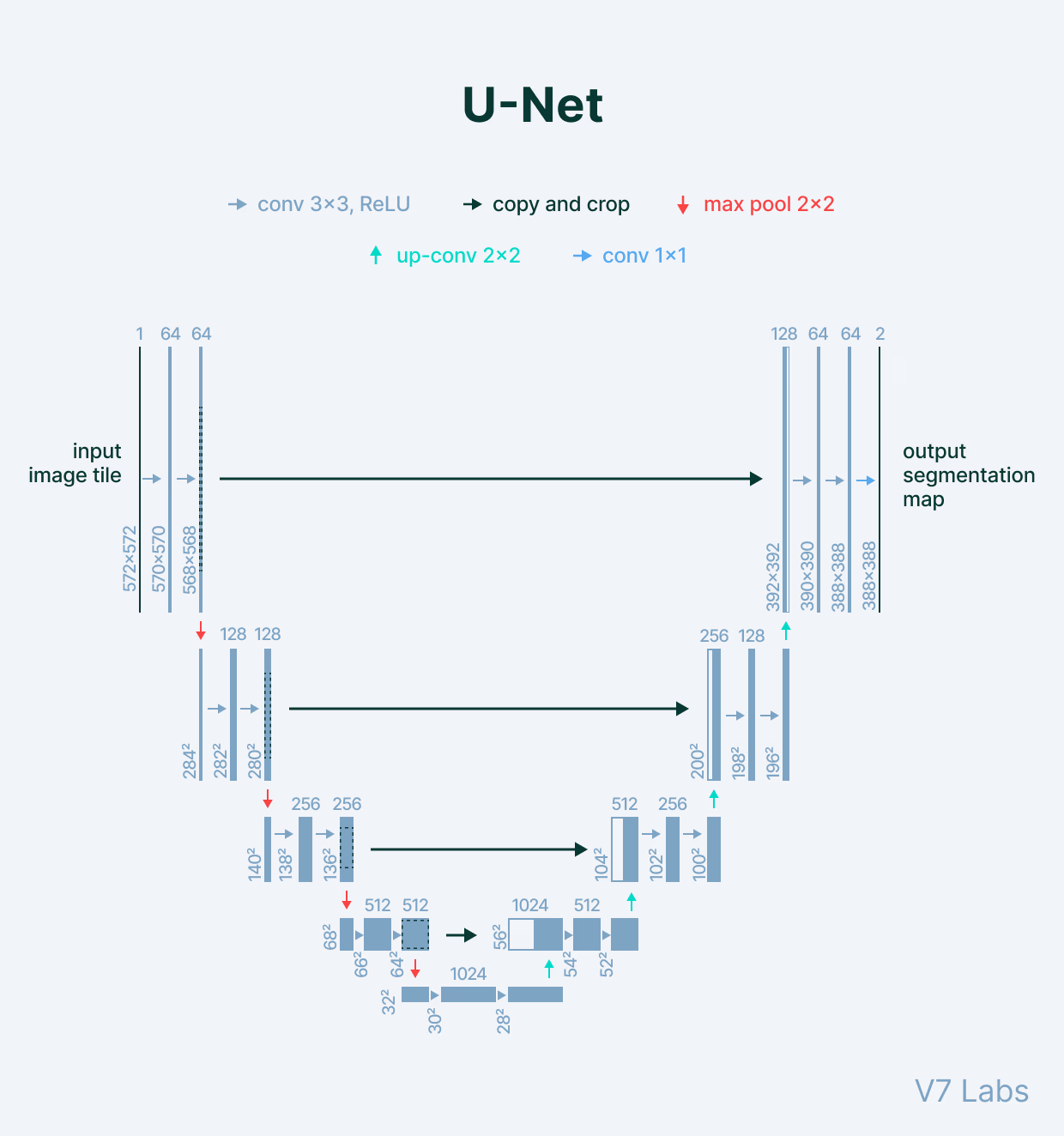
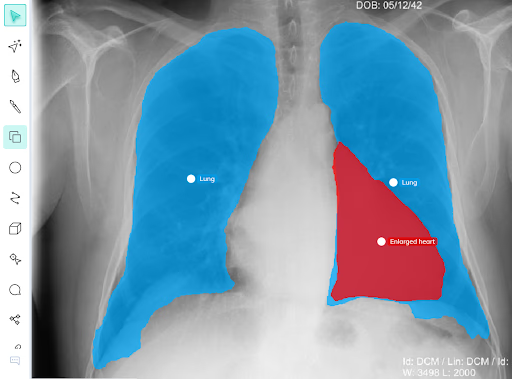
https://link.springer.com/article/10.1007/s10462-023-10621-1
4.Likt pašiem implementēt UNet ar concat un parādīt, ja nepieciešams
6.Likt pašiem implementēt UNet ar addition un parādīt, ja nepieciešams
8.YOLO uzdevums
xxxxxxxxxx11pip install ultralytics
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information.

COCO Dataset
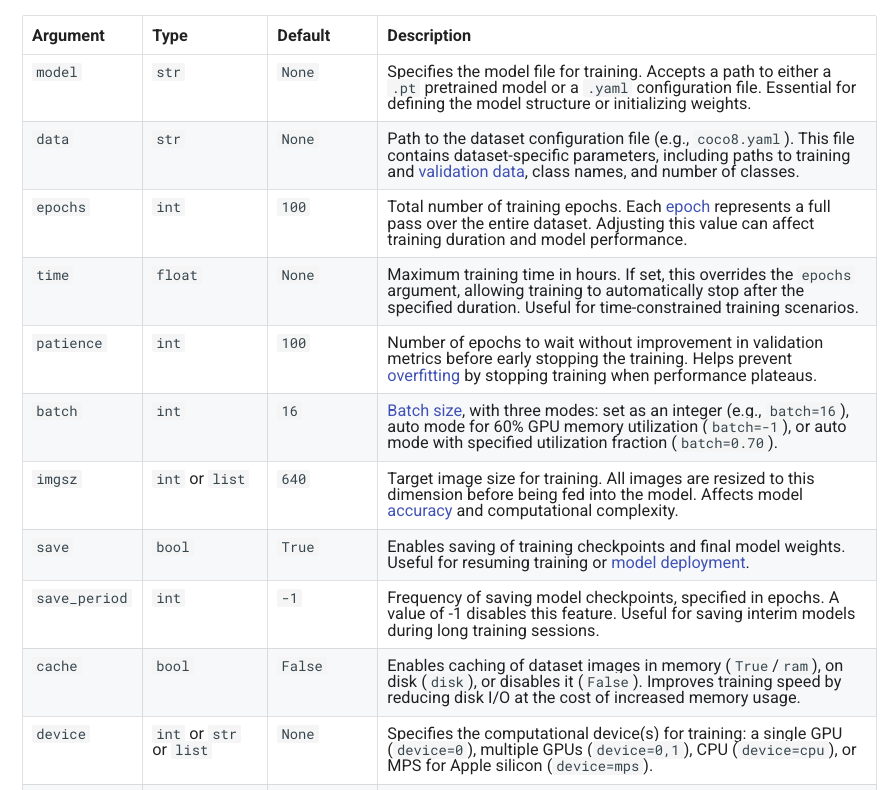
Training parameters https://docs.ultralytics.com/modes/train/#train-settings
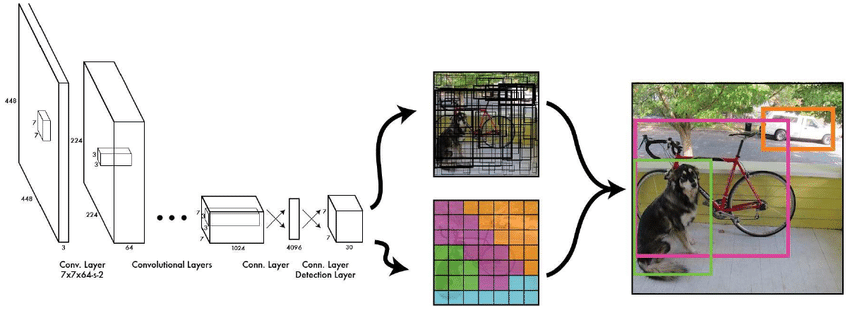
https://www.researchgate.net/figure/Pipeline-of-YOLOs-algorithm-12_fig1_350090136

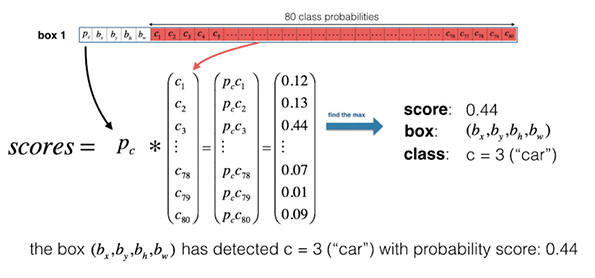
Non-max surpression algorithm

Oriented Bounding Boxes
Oriented object detection goes a step further than standard object detection by introducing an extra angle to locate objects more accurately in an image.
The output of an oriented object detector is a set of rotated bounding boxes that precisely enclose the objects in the image, along with class labels and confidence scores for each box. Oriented bounding boxes are particularly useful when objects appear at various angles, such as in aerial imagery, where traditional axis-aligned bounding boxes may include unnecessary background.

https://docs.ultralytics.com/tasks/obb/
10.2. Implementēt UNet modeļa forward funkciju ar concat
Pirmkoda sagatave pieejama šeit: http://share.yellowrobot.xyz/quick/2023-11-16-C31604C9-53E7-49D2-8D21-B13FF215C139.zip
Implementēt UNet modeļa forward funkciju ar concat, Vienādojumi pieejami šeit:
Iesniegt ekrānšāviņus un pirmkodu.
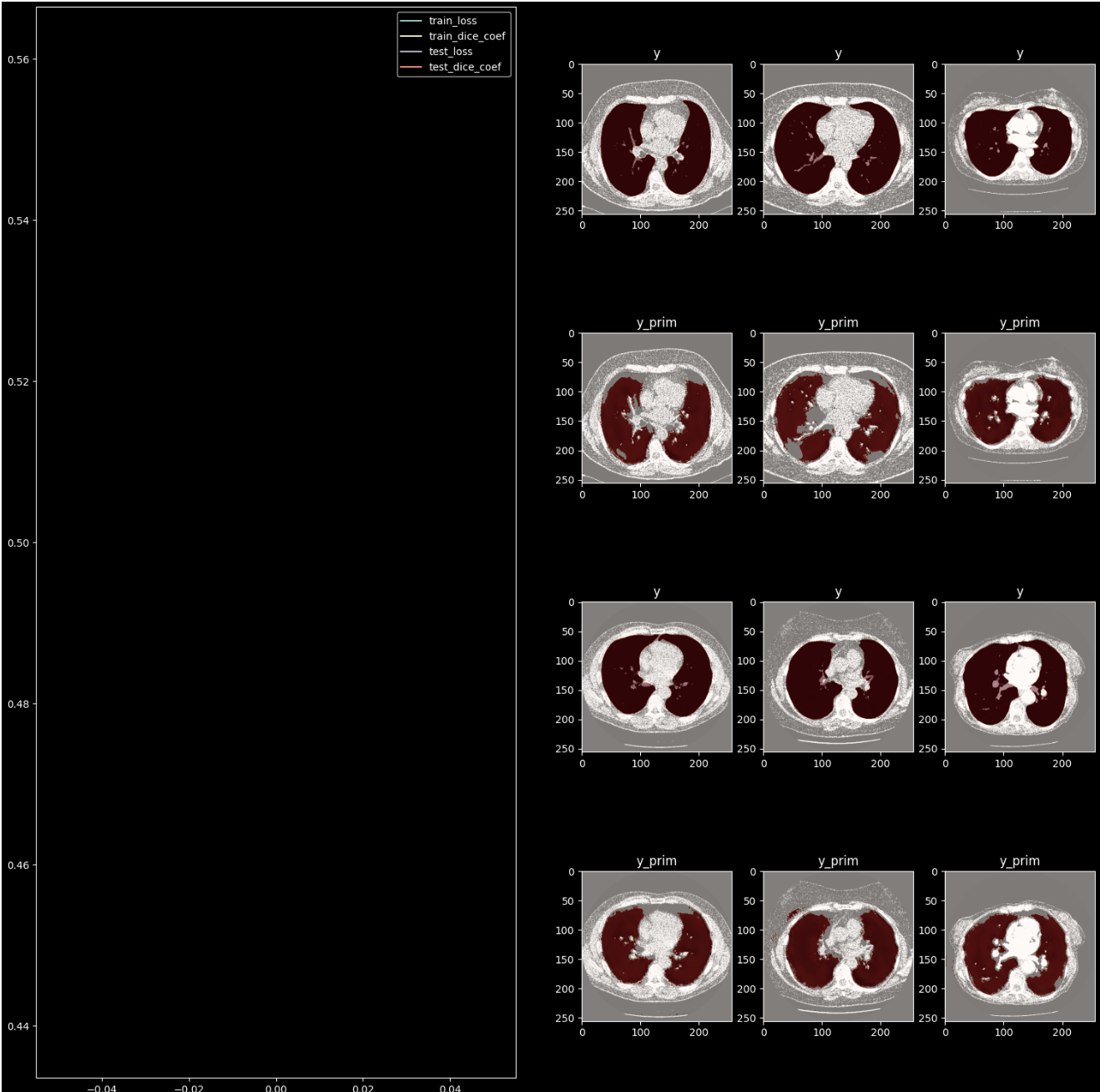
10.3. Implementēt UNet modeļa forward funkciju ar saskaitīšanu
Izmantot iepriekšējā uzdevuma sagatavi, Implementēt UNet modeļa forward funkciju ar saskaitīšanu. Nepieciešams arī izmainīt modeļa struktūru (kanālu skaitu).
Vienādojumi pieejami šeit:
Iesniegt ekrānšāviņus un pirmkodu.
10.4. Implementēt UNet modeli ar LinearLayer pa vidu
Izmantot iepriekšējā uzdevuma sagatavi, Implementēt UNet modeļa forward funkciju ar LinearLayer pa vidu. Šāds modelis jāsagatavo tā, lai tas spētu strādāt ar iepriekš zināmu input attēla izmēru atšķiribā no FCN (Fully Convolutional Network) kādi bija iepriekšējie modeļi.
Vienādojumi pieejami šeit:
Iesniegt ekrānšāviņus un pirmkodu.
10.5. Implementēt objektu atpazīšanu COCO kopā, izmantojot YOLO
Balstoties uz video instrukcijām implementēt objektu atpazīšanu COCO kopā, izmantojot YOLO. Sagatave:
https://share.yellowrobot.xyz/quick/2025-4-21-539AB043-B601-4C2F-93A5-01D682274BC5.zip

Iesniegt ekrānšāviņus un pirmkodu.
10.6. Mājasdarbs. Implementēt DICE kļūdu un IoU metriku
Pie iepriekšēja uzdevuma pievienot DICE kļūdu - izmantot kā kļūdas funkciju (izveidot kompozīta kļūdas funkciju ar koeficientiem katrai kļūdas funkcijas daļai)
Pievienot metriku IoU, attēlot to grafiski (Jaccard index)
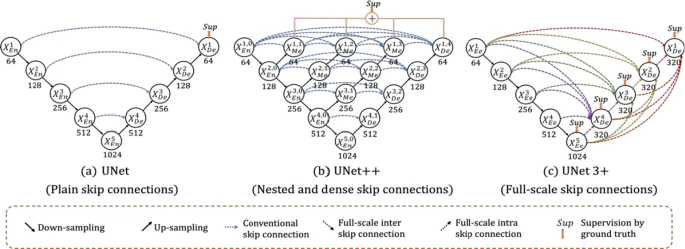
Papildus uzdevums - Implementēt UNet++ arhitektūru: https://arxiv.org/pdf/1807.10165
Apmācīt modeļus ar jaunajām izmaiņām iesniegt ekrānšāviņus un pirmkodu.