2025-Q1-AI 14. ViT Vision Transformers
14.1. Video / Materiāli (🔴 13. maijs 18:00, Riga, Zunda krastmala 10, 122)
Zoom / Video pēc tam: https://zoom.us/j/3167417956?pwd=Q2NoNWp2a3M2Y2hRSHBKZE1Wcml4Zz09
Materials:
Iepriekšējā gada video: https://www.youtube.com/live/VKvUQP1pkcU
Finished code download: http://share.yellowrobot.xyz/quick/2023-12-26-6D6B4B78-1645-4CD7-BBF2-6A2B3D199AC2.zip
14.2. Implementēt ViT
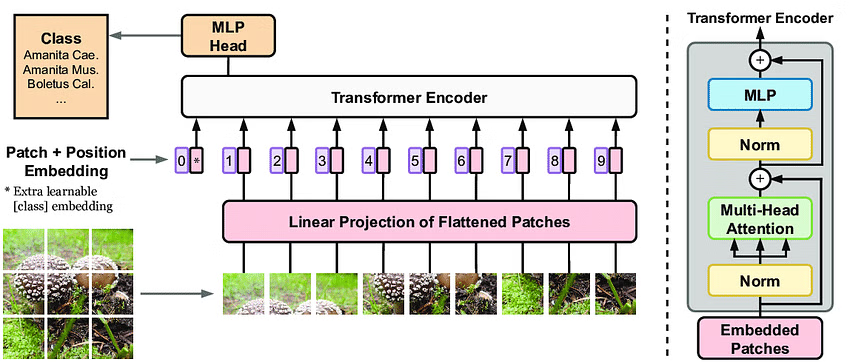
Sekot līdzi video un implementēt ViT (An Image is Worth 16x16 Words) https://openreview.net/forum?id=YicbFdNTTy
Template: http://share.yellowrobot.xyz/quick/2023-4-17-5C413CBF-48AA-4BEC-9D1B-223AE9B27E77.zip
Iesniegt pirmkodu un screenshot ar rezultātiem.
14.3. Implementēt modeli ar talonu mācīšanos
Implementēt talonu mācīšanos izmantojot 14.2 pirmkodu un pievienot “ViT Token learner” pēc publikācijas https://arxiv.org/pdf/2106.11297.pdf Paraugs pirmkodam: https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
Iesniegt pirmkodu un screenshot ar rezultātiem, salīdzināt rezultātus ar un bez “ViT Token learner”
ViT Token learner: https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
ViViT: A Video Vision Transformer https://arxiv.org/pdf/2103.15691.pdf
VNT-Net: Rotational Invariant Vector Neuron Transformers https://arxiv.org/pdf/2205.09690.pdf
First introduced in An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale19 https://iaml-it.github.io/posts/2021-04-28-transformers-in-vision/
Vision Transformers (ViT) Explained: Are They Better Than CNNs?
https://towardsdatascience.com/vision-transformers-vit-explained-are-they-better-than-cnns/
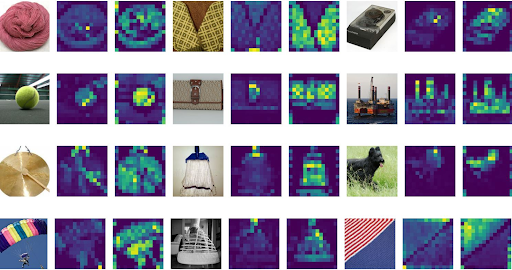

Filters of the initial linear embedding layer of ViT-L/32 (left) [3]. The first layer of filters from AlexNet (right) [6].
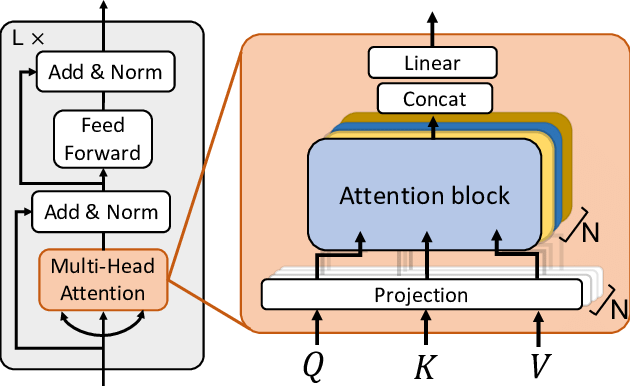
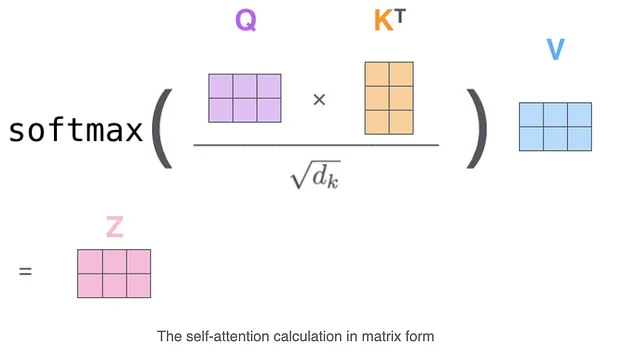
https://medium.com/@gabell/encoder-decoder-models-and-transformers-5c1500c22c22
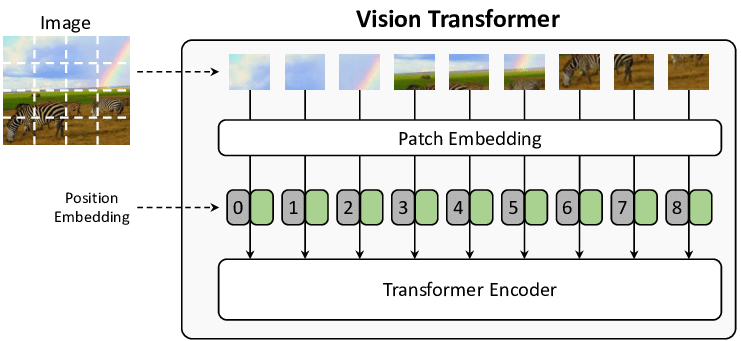
https://hossboll.medium.com/generalizing-transformers-for-processing-images-a6b5c394d0e0
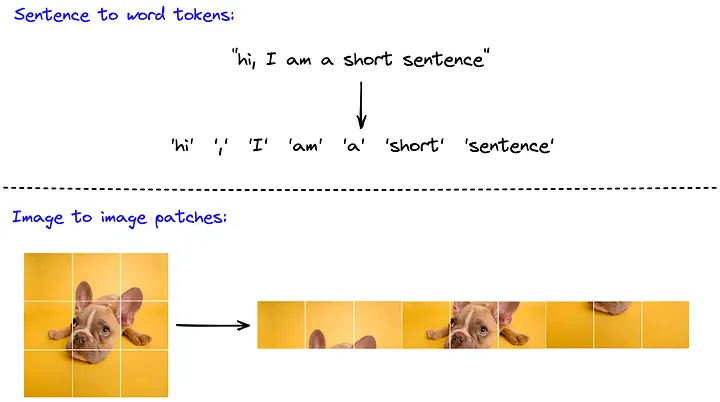
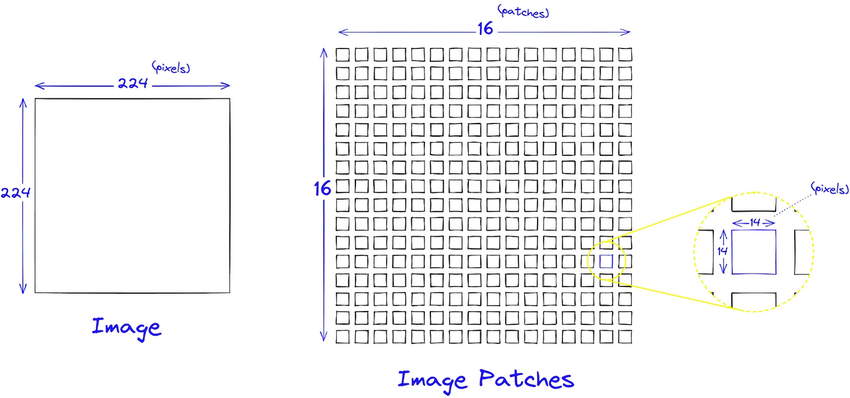
https://www.pinecone.io/learn/series/image-search/vision-transformers/
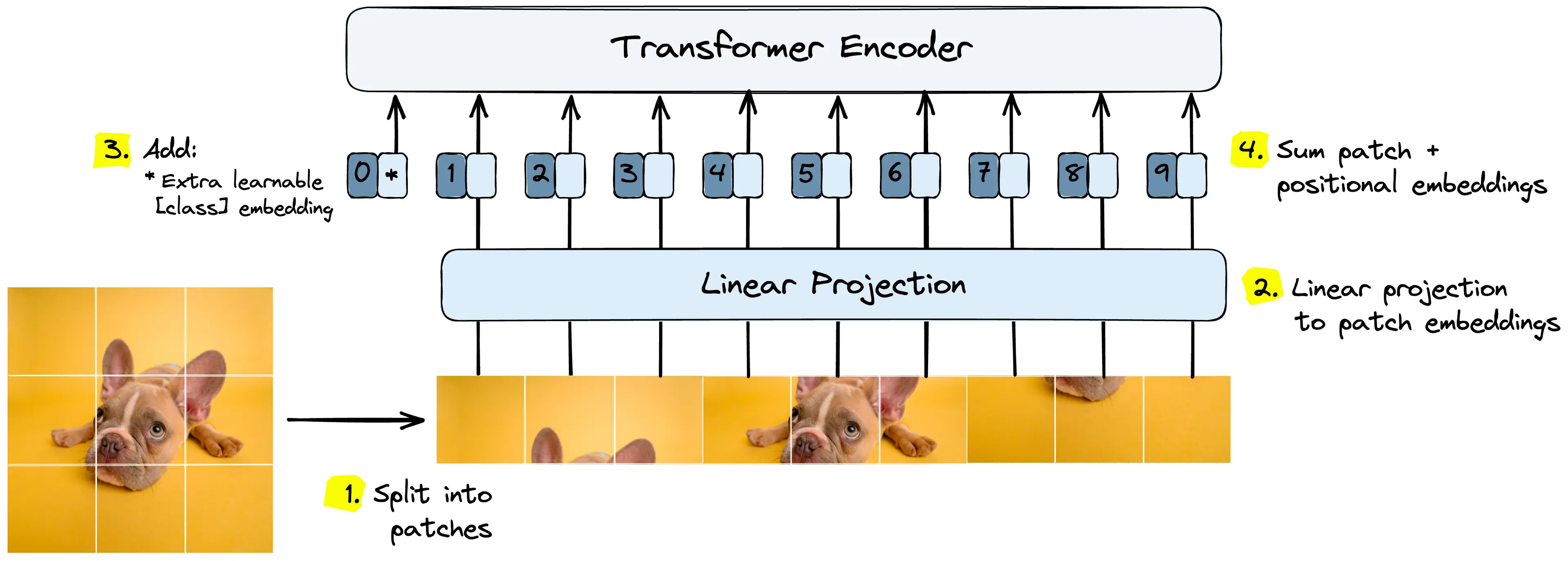
https://towardsdatascience.com/vision-transformers-vit-explained-are-they-better-than-cnns/
https://viso.ai/deep-learning/vision-transformer-vit/
Class Activation map

https://jacobgil.github.io/deeplearning/vision-transformer-explainability
https://github.com/jacobgil/vit-explain


Step by step code: https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial15/Vision_Transformer.html
https://keras.io/examples/vision/probing_vits/
Good material:
https://iaml-it.github.io/posts/2021-04-28-transformers-in-vision/ https://www.pinecone.io/learn/vision-transformers/
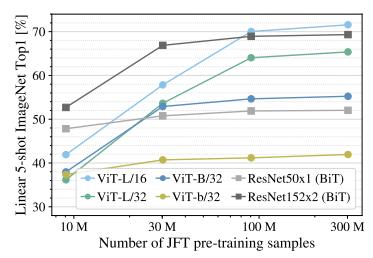
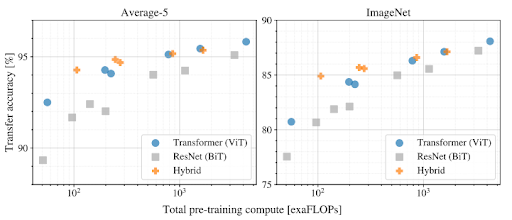
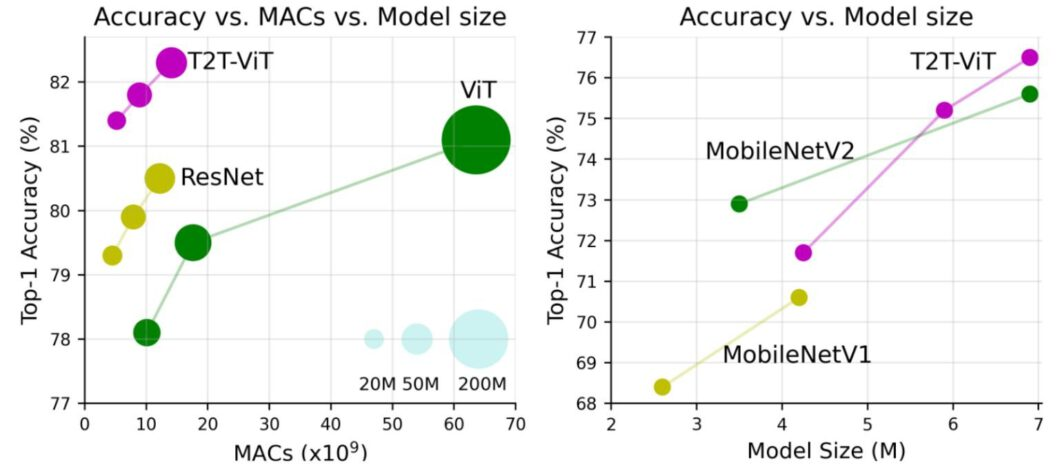
In Vision Transformers, images are represented as sequences of patches, where every patch is flattened into a single vector by concatenating the channels of all pixels in a patch and then linearly projecting it to the desired input dimension . The number of patches increases as we increase the resolution, leading to higher memory footprint. TokenLearner can help reduce the number of patches without having to compromise performance
First, divide the input image into a sequence of small patches. Then, use the TokenLearner module to adaptively generate a smaller number of tokens. Process these tokens through a series of Transformer blocks. Finally, add a classification head to obtain the output.
from tokenlearner import TokenLearnerModuleV11
tklr_v11 = TokenLearnerModuleV11(in_channels=128, num_tokens=8, num_groups=4, dropout_rate=0.) tklr_v11.eval() # control dropout x = torch.ones(256, 32, 32, 128) # [bs, h, w, c] y2 = tklr_v11(x) print(y2.shape) # [256, 8, 128]
Tad, kad laidu ar konfigurāciju,
ko izmantojām 14.2 uzdevumā, ievērojamu atšķirību starp ViT
ar un bez TokenLearner nemanīju (varbūt ~5% improvement iterāciju ātrumā labākajā gadījumā).
Tāpēc pamēģināju modeli palielināt. Palielināju transformeru layer skaitu uz 4 un n_patches uz 14.
Modelis sasniedza ~99% accuracy pa aptuveni 20 epochs ar vidēji 26 iterācijām sekundē.
Tad aiz pirmā transformer slāņa pieliku TokenLearner ar learned_tokens=2.
Modelis sasniedza to pašu ~99% accuracy pa aptuveni tik pati epochiem, bet ar vidēji 72 itērācijām sekundē, kas ir ~2.75x uzlabojums.
Nezinu, vai tas ir īpaši godīgs salīdzinājums tā kā datasets varētu nebūt pats sarežģītākais, bet skaitļi ir patīkami, tāpēc ¯_(ツ)_/¯
Slides
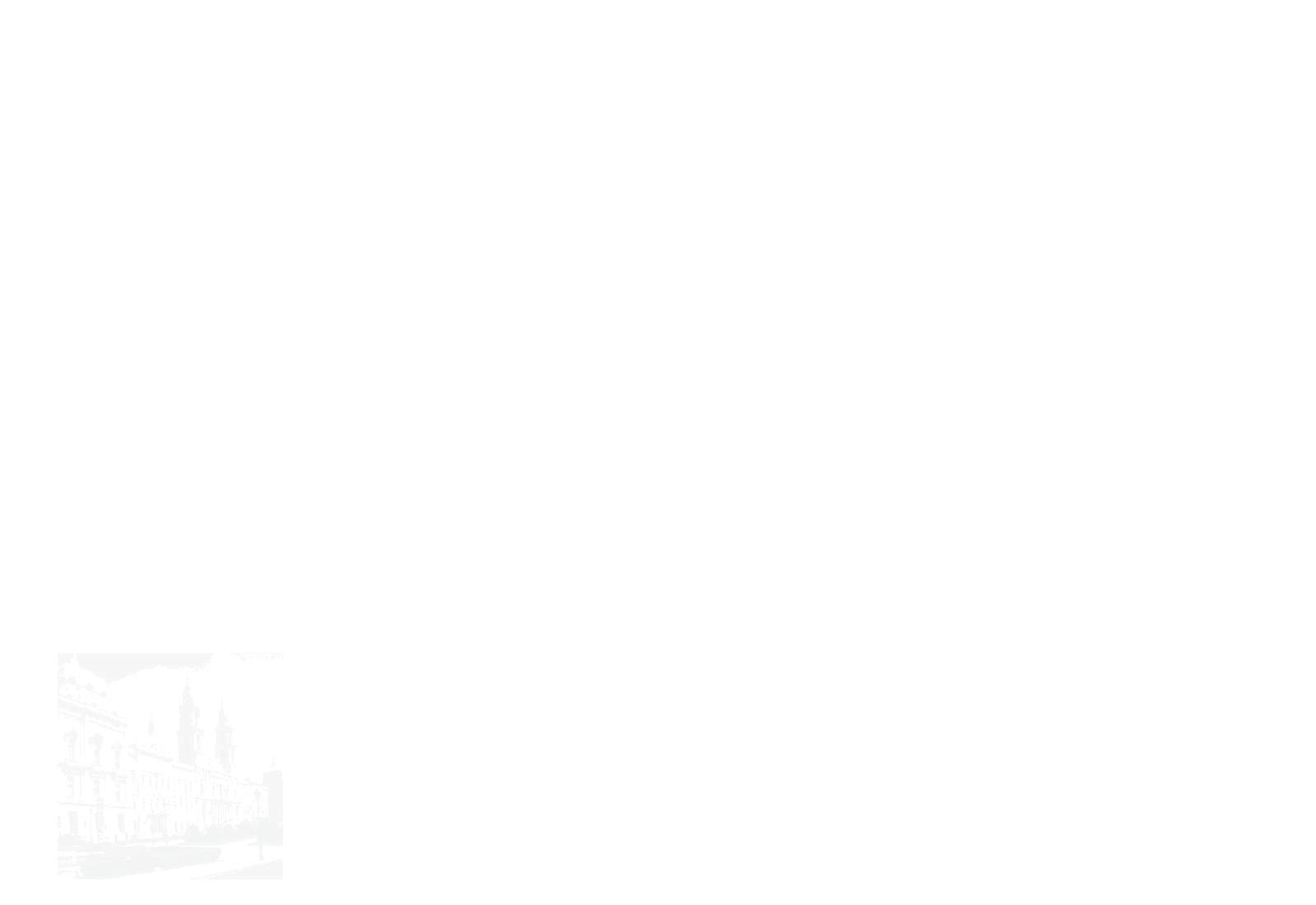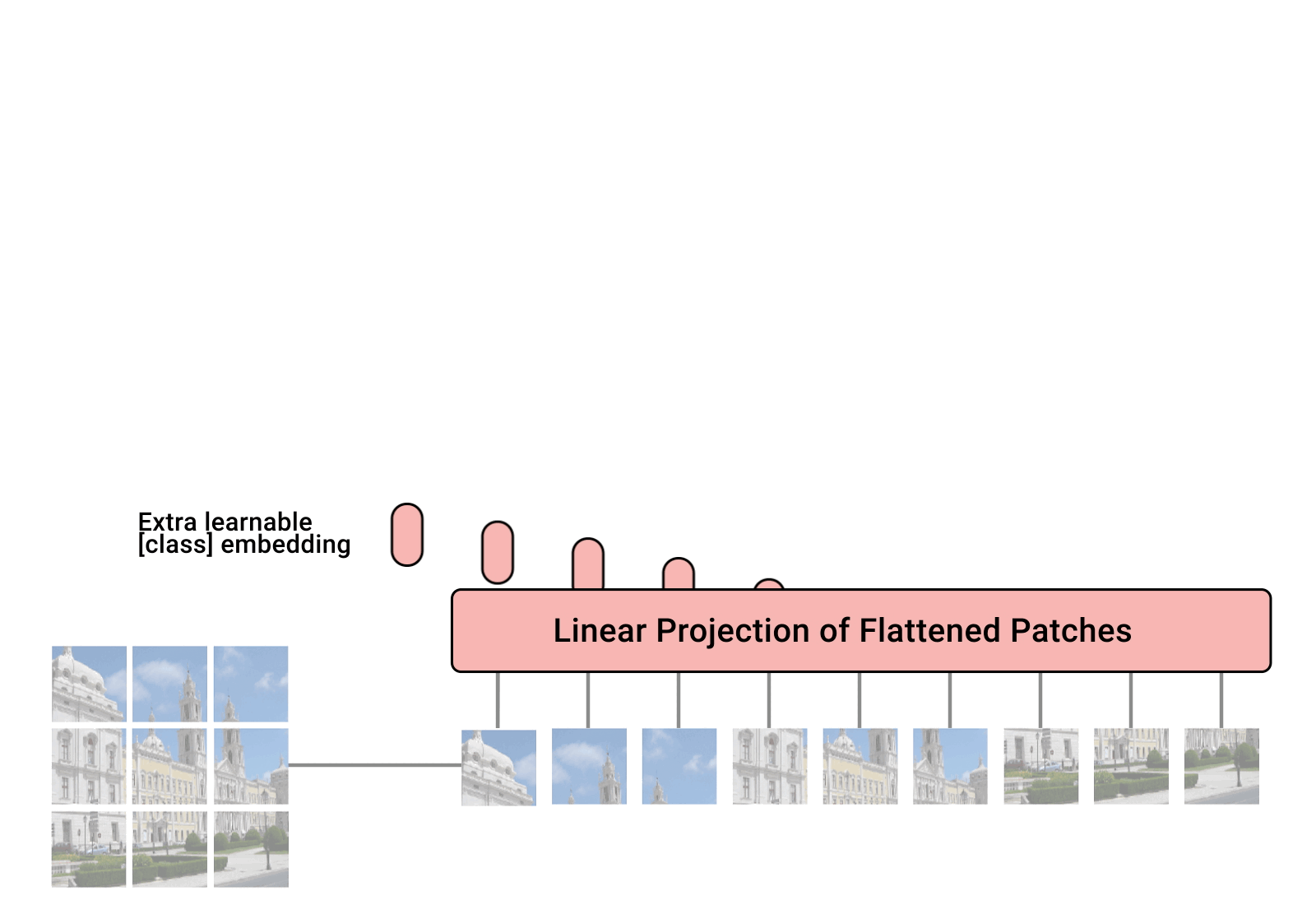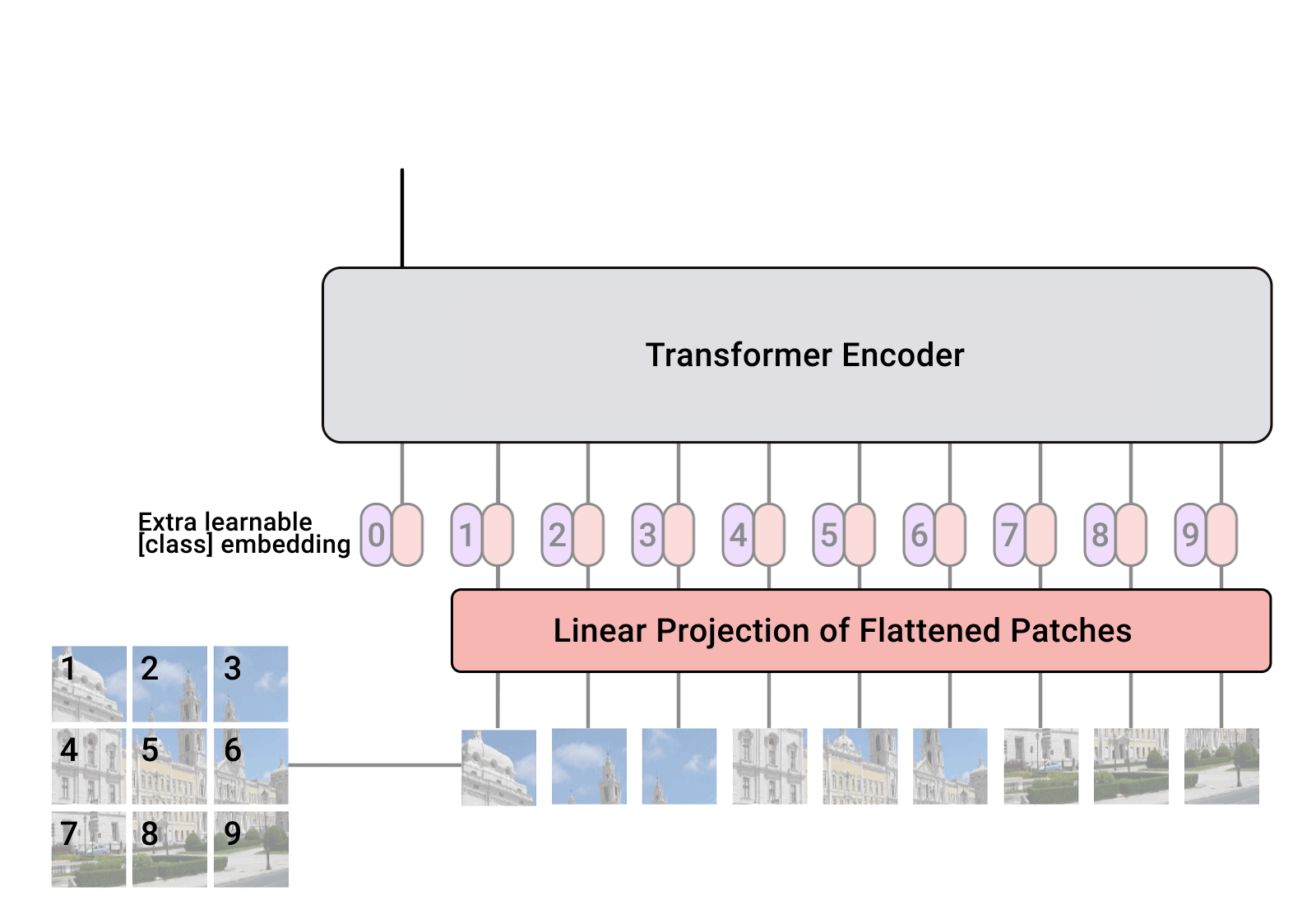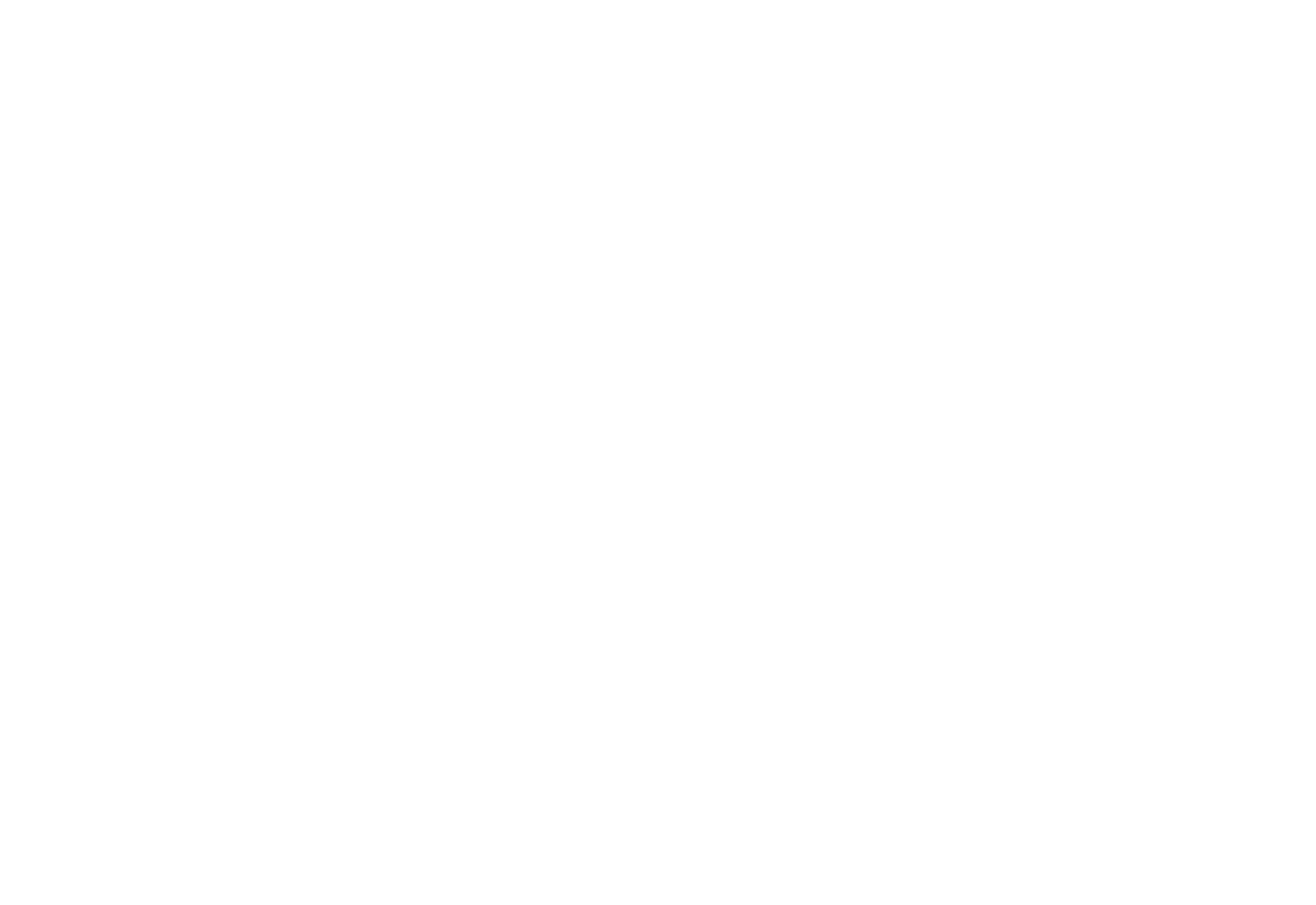
Tips - tricks
https://theaisummer.com/transformers-computer-vision/
? Patches, ovelapping
? conv vs linear patch
? multiple tokens classifying => BCE not CCE