2025-Q1-AI 15. DQN DDQN
15.1. Video / Materials (🔴 20. maijs 18:00, Riga, Zunda krastmala 10, 122)
Zoom / Video pēc nodarbības: https://zoom.us/j/3167417956?pwd=Q2NoNWp2a3M2Y2hRSHBKZE1Wcml4Zz09
Whiteboard: https://www.figma.com/board/tqfLc2NBg8SKAPWVJiW3cL/2025-Q1-AI-15.-DQN-DDQN?node-id=0-1&t=jK9OBcxX8PFTsyrZ-1
Sagatavošanās materiāli: Rainbow DQN: https://arxiv.org/abs/1710.02298 https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html https://medium.freecodecamp.org/an-introduction-to-reinforcement-learning-4339519de419
Iepriekšējā gada video
Video https://youtu.be/tiaoLNMWZUA
https://youtube.com/live/LdMZxZCnOYE?feature=share
Pabeigts pirmkods:
https://share.yellowrobot.xyz/quick/2024-5-16-D405A821-6724-4093-8D02-44E423555721.zip
https://share.yellowrobot.xyz/quick/2024-5-7-B0676B73-317D-4B10-9015-49304BA00A70.zip
GOOGLE COLAB fix
xxxxxxxxxx21!pip install swig2!pip install gymnasium[box2d]
15.2. Implementēt DQN
Balstoties uz 14.1. materiāliem un video implementēt DQN, izmantojot sagatavi.
Iesniegt kodu un ekrānšāviņus ar rezultātiem.
requirements.txt: https://share.yellowrobot.xyz/quick/2024-5-7-F3F3DD22-6A51-4328-BE43-4DDAA91E50E4.zip
Template: https://share.yellowrobot.xyz/quick/2024-5-7-817F6F38-5604-480F-A879-457AE8C4B767.zip
Vienādojums:
15.3. Implementēt DDQN
Implementēt DDQN, balstoties uz uzdevuma sagatavi: https://share.yellowrobot.xyz/quick/2024-5-7-8D323D7A-938E-4077-A6FF-FE3B068E2941.zip
Iesniegt kodu un ekrānšāviņus ar rezultātiem.
Vienādojums:
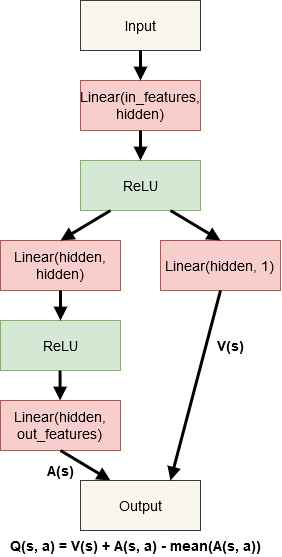
15.4. Mājasdarbs - Dueling DDQN, MountainCar
Balstoties uz 14.3 kodu, implementēt jaunu vidi MountainCar: https://gym.openai.com/envs/MountainCar-v0
Implementēt Dueling DDQN modeļa arhitektūru https://arxiv.org/abs/1511.06581
Implementēt pēc iespējas vairāk komponentes no Rainbow DQN https://arxiv.org/pdf/1710.02298
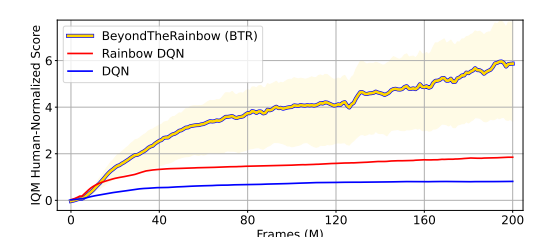
Implementēt pēc iespējas vairāk komponentes no BTR (Beyond the Rainbow) https://arxiv.org/pdf/2411.03820
Iesniegt kodu un ekrānšāviņus ar rezultātiem.
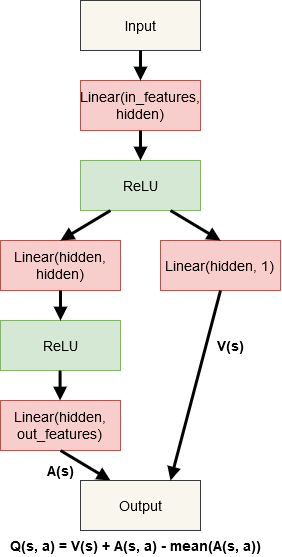
Modeļa shēma:
Saturs
Izskaidrot basics par RL, ka nevajag labels, vajag tikai vidi vai Reward modeli
Izskaidrot terminus
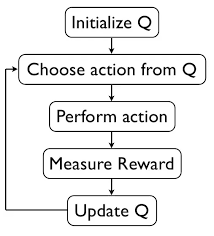
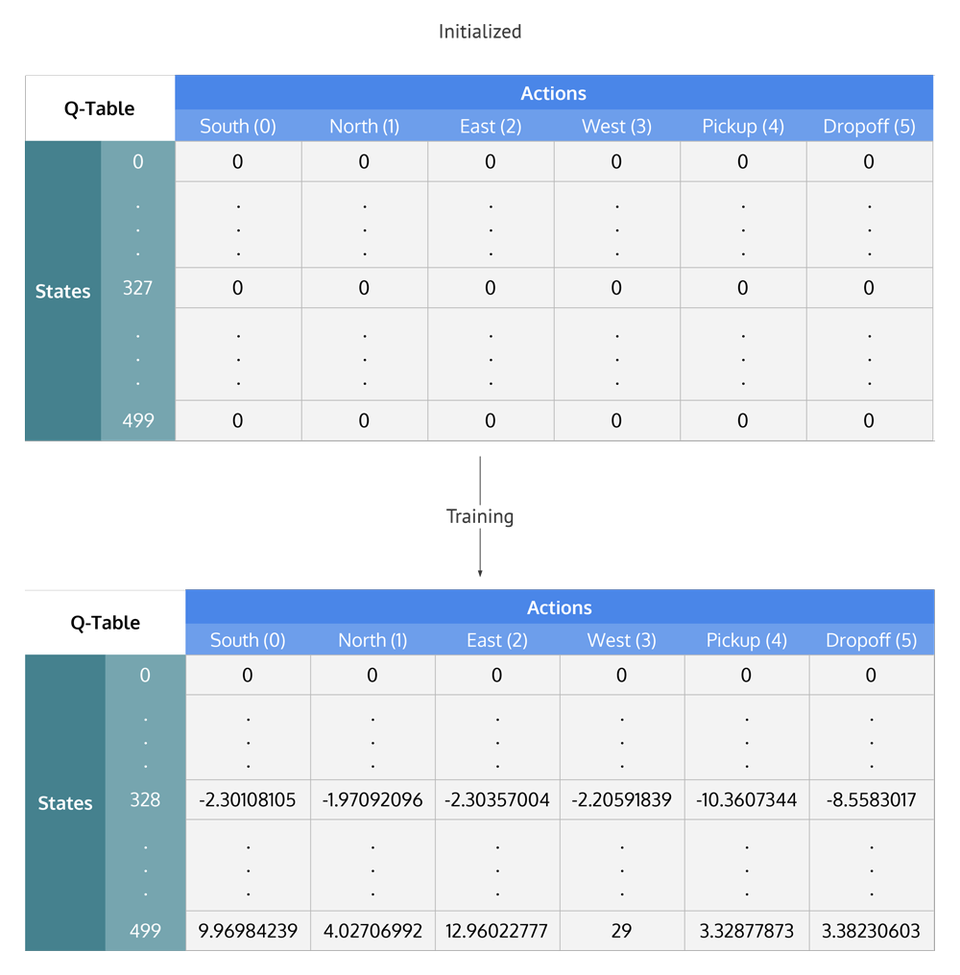
Q-Tables un Kumulatīva R
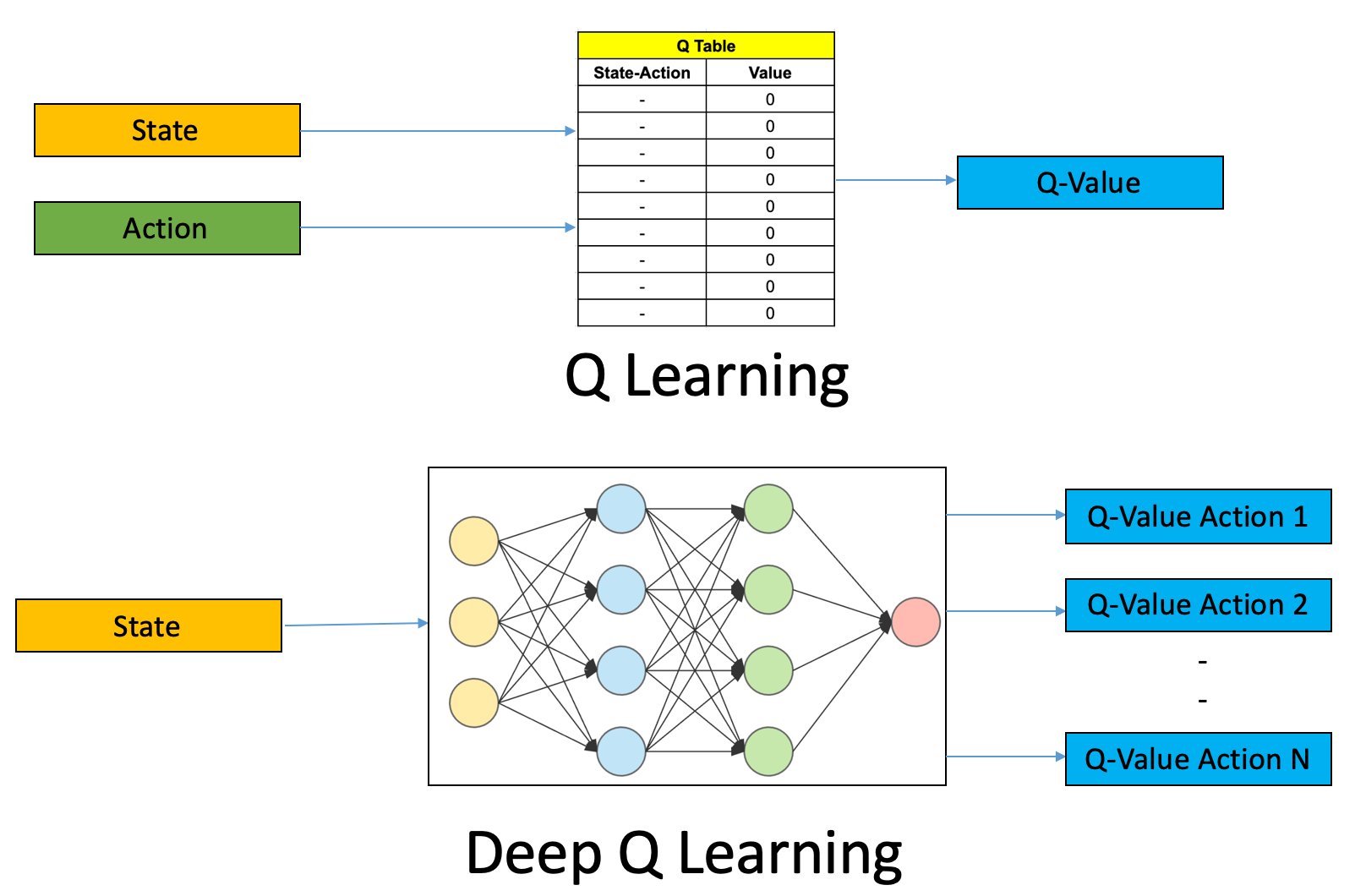
DQN (Deep Q-Network)
Terminoloģija
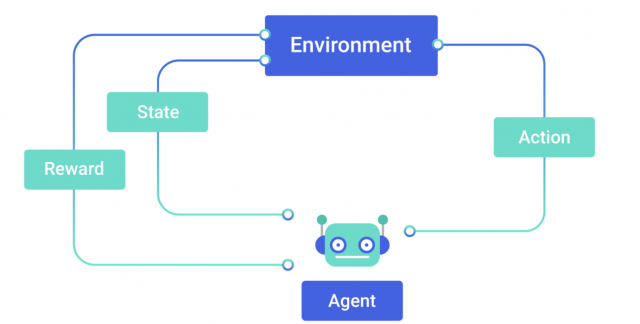
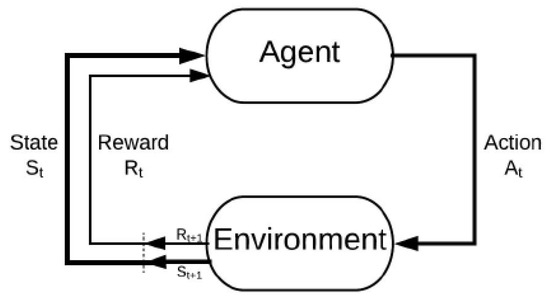
Aģents (agent) — apmācāmais un lēmumu pieņēmējs.
Vide (environment) — kur aģents mācās un izlemj, kādas darbības veikt.
Darbība (action) — darbību kopums, ko aģents var veikt.
Stāvoklis (state) — aģenta stāvoklis vidē.
Atlīdzība (reward) — par katru aģenta izvēlēto darbību vide nodrošina atlīdzību; parasti skalāra vērtība.
Epizode (Episode) - Darbību un stāvokļu kopums no sākuma līdz beigu stāvoklim (Terminālais stāvoklis).
Trajektorija (Trajectory) - Visi stāvokļu un darbību pāri vienas epizodes ietvaros.
Horizonts (Horizon) - Cik soļus paturēt atmiņā vienas epizodes ietvaros.
Politika (Policy) — aģenta lēmumu pieņemšanas funkcija (kontroles stratēģija), kas atspoguļo kartēšanu no situācijas uz darbībām.
Vērtības funkcija (Value function) — kartēšana no stāvokļiem uz reāliem skaitļiem, kur stāvokļa vērtība atspoguļo ilgtermiņa atlīdzību, kas iegūta, sākot no šī stāvokļa un izpildot noteiktu politiku.
Bezmodeļa pieeja (Model-Free RL) — nosaka optimālo politiku, neizmantojot vai nenovērtējot vides dinamiku (pārejas un atlīdzības funkcijas)
Balstīta uz modeli (Model-based RL) — izmanto pārejas funkciju (un atlīdzības funkciju), lai novērtētu optimālo politiku
Materials
https://vitalflux.com/different-types-of-machine-learning-models-algorithms/
https://www.mdpi.com/1424-8220/22/21/8278
https://zhuanlan.zhihu.com/p/34076237
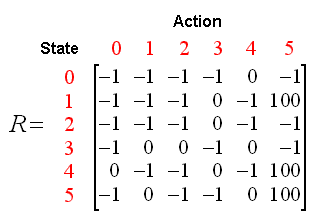
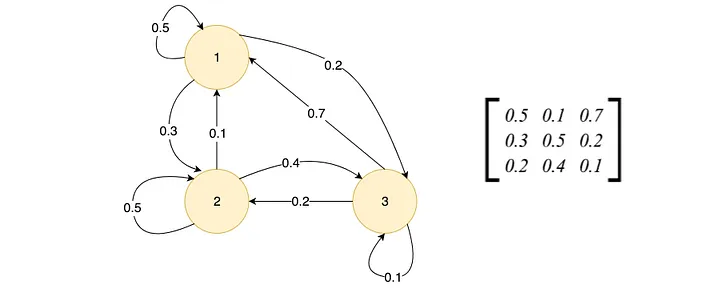
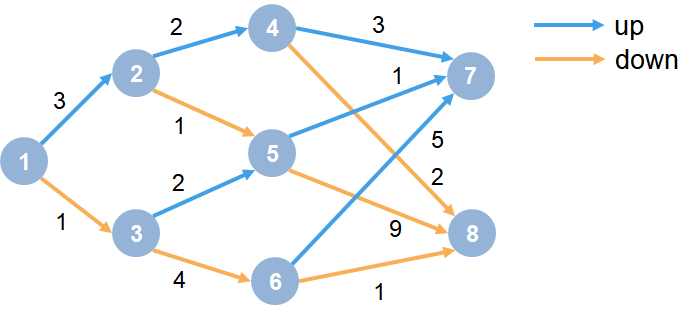
Pa labi savienojamības matrica - S1, S2, S3 un Reward vērtība pārejai
Markova lēmumu pieņemšanas process (Markov Decision Processs - MDP) - teorija matemātikā, kas ļauj modelēt lēmumu pieņemšanu vidē ar diskrētu laiku. Pašreizējais stāvoklis rakstro visu iepriekšējo stāvokļu trajektoriju.
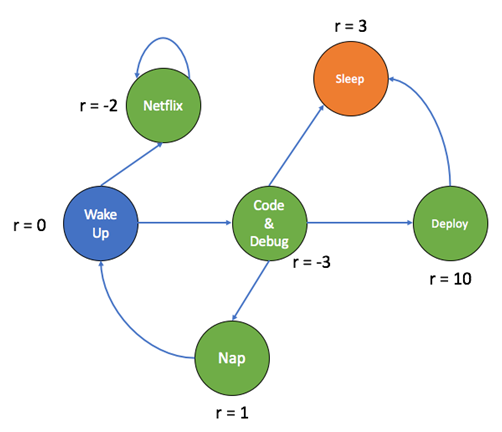
Q Vērtības (jeb to aproksimācijas funkcija) norāda uz potenciālo kumulatīvo R vērtību nākotnē katrā stāvoklī kurā aģents atrodas. Senāk Q tabulās tā sakrita ar diskonta kumulatīvo R vērtību, bet mūsdienu modeļos tā var atšķirties, taču funkcija ir tā paša.
Kumulatīva atlīdzība (Reward) ar diskouna faktoru
Gamma = discount factor, kas nosaka cik nākotnes atlīdziba ir svarīga salīdzinājumā ar tuvāka stāvokļa atlīdzību. Piemēram, Flappy Bird spēlē svarīgākas ir tuvākas atlīdzinas, nevis ilgtermiņa atlīdzības.
Short-term focus: choose a small γ (e.g., 0–0.3). Rewards more than a few steps away are heavily down-weighted.
Long-term focus: choose a large γ (e.g., 0.9–0.999 —or exactly 1.0 in a finite-horizon task). Future rewards are almost as valuable as immediate ones.
Laika atskaite sākas no pašreizējā laika soļa līdz terminālajam stāvoklim nākotnē t.
Belmana vienādojums (Q-Learning)
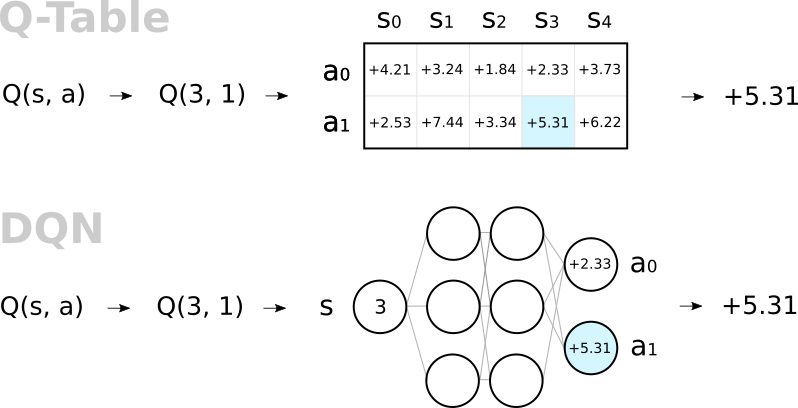
DQN (Deep Q-Network)

Q-Learning vs DQN
https://valohai.com/blog/reinforcement-learning-tutorial-basic-deep-q-learning/
DDQN (Double Deep Q-Network)
Stabilāka apmācība, jo ar noteiktu laika intervālu tiek izmantota zināma pēdējā Q funkcija nevis Q funkcija, kura dinamiski mainās pie katras darbības.
Izpēte pret eksplotāciju (Explorations vs Explotation)

https://medium.com/swlh/using-q-learning-for-openais-cartpole-v1-4a216ef237df
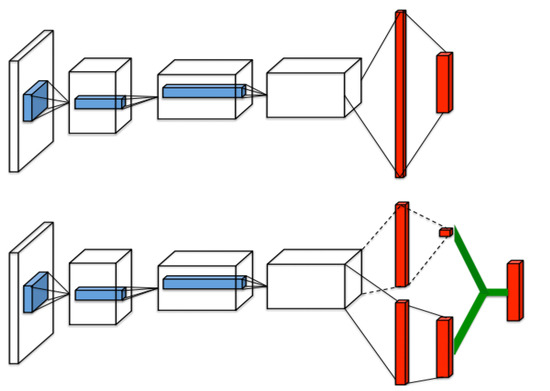
Dueling DDQN
https://www.mdpi.com/2076-3417/12/7/3520
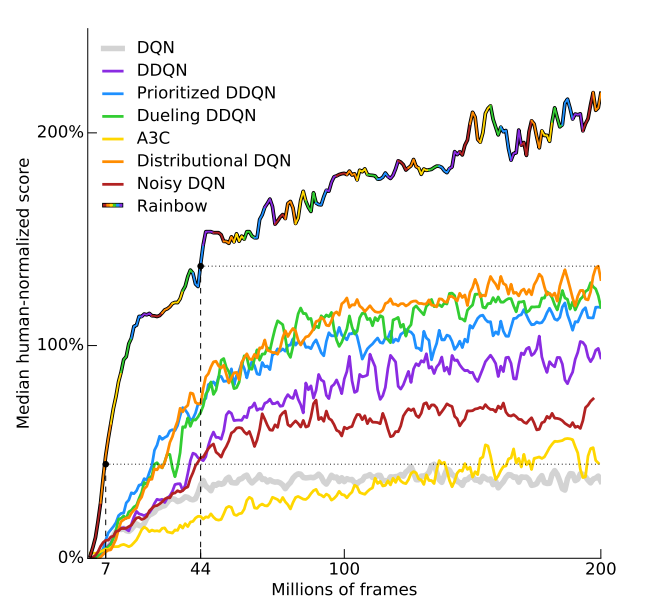
Rainbow DQN kombinācija
https://arxiv.org/pdf/1710.02298
BEYOND THE RAINBOW: HIGH PERFORMANCE DEEP REINFORCEMENT LEARNING ON A DESKTOP PC - BTR
https://arxiv.org/pdf/2411.03820