2025-05-18 Meeting 3
TODO
Pārrakstīt hipotēzi pēc dotajiem komentāriem
Nelietot vārdu “Kategorijas”. “Kategorizēto rezultātu analīze pēc attēlu tipiem” pārsaukt “Attēlu kvalitātes rādītāju salīdzinājums katrai datu kopai”, izmanotot Spearman R
“Atsevišķu gadījumu analīze…” pārsaukt “Sliktāko un labāko paraugu kvalitatīvs salīdzinājums katrai datu kopai”
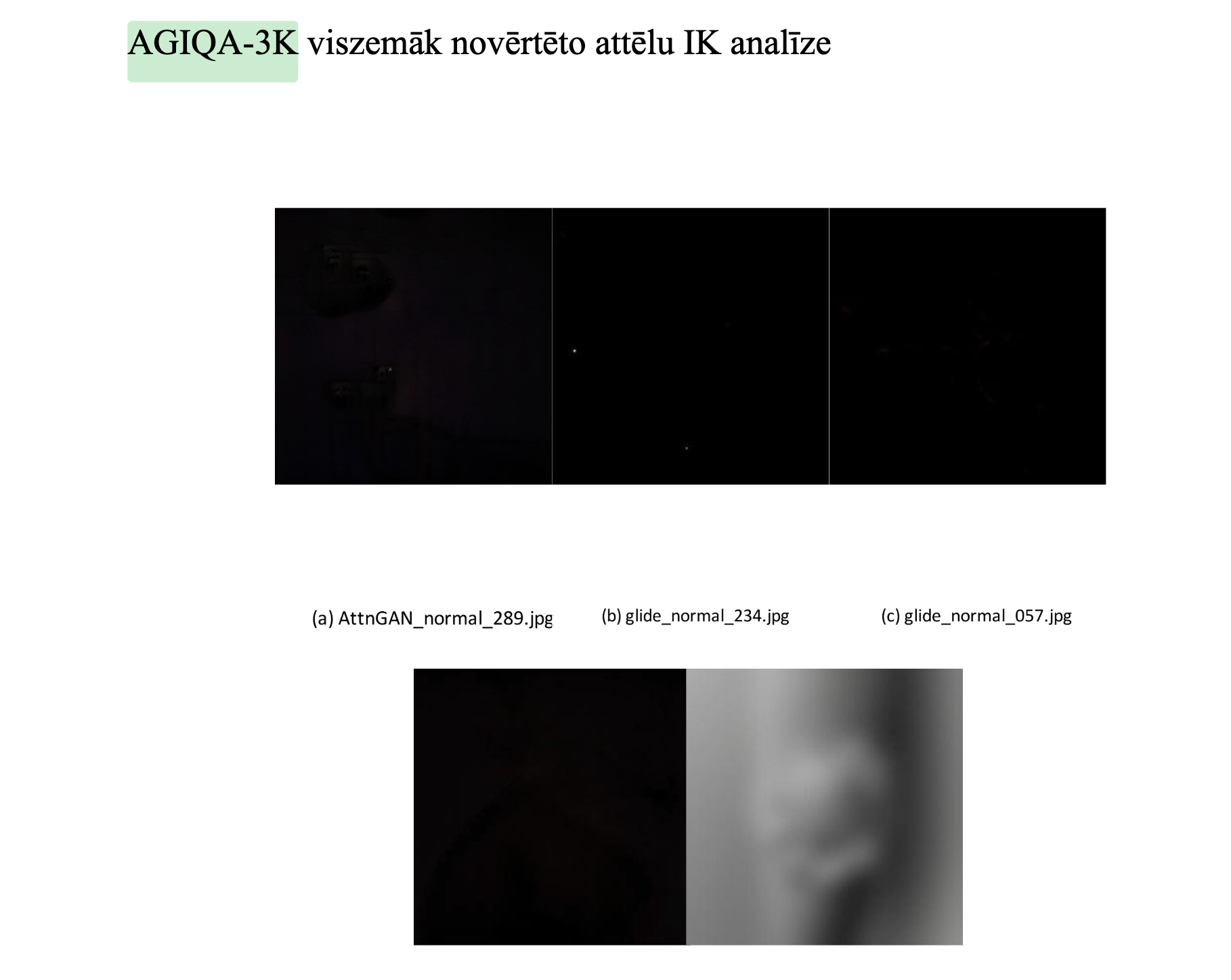
Vajadzētu aizvākt dupliklātus attēliem un melnos attēlus - vajadzētu cherry pickot labākus paraugus
Vajadzētu iekrāsot rezultātus pēc kopējās skalas (kaut vai globālas) nevis 5 paraugu ietvaros
Salabot, ka nodaļas ir par katru datu kopu un blakus redzami labie un sliktie piemēri uzskatāmi
“Rādītāju duplikāciju…” pārsaukt “Vidējo rādītāju salīdzinājums ar MOS starp apvienotām datu kopām”
Izmantot Pearson R un nerunāt neko par Spearman R
Secinājumos shēmu balstīt tikai uz korelāciju matricām, ideāli, ja būtu ranga tabula pēc kuras izvēlēties metodi un pamatot hipotēzi
Pārrakstīt ar ChatGPT CLIP, LIQE, RankingCLIP metožu aprakstus ar tādu valodu, kuru tu pats spēj izskaidrot, šobrīd, piemēram, vārds “kategorija” pilnīgi citā kontekstā lietots un nav loģiski skaidrojumi kāpēc attēlu kvalitātes novērtēšanai vajag text encoders, visticamāk CLIP image encoder pietiek. Jābūt aprakstītam rezultātu vērtību robežām, ko tās apraksta un kā metode aptuveni strādā.
Piedāvājumi satura rādītāja uzlabojumiem!
Sistemātisks literatūras apskats 8 1.2. Attēlu kvalitātes novērtēšanas rādītāji 14
1.2.1. Rādītāju klasifikācija un novērtēšanas kritēriji 14
Aizliegts lietot vārdu “klasifikācija” šajā kontekstā.
Jāpievieno iepriekšējai nodaļai vai jāizdala: Klasiskie novērtēšanas attēlu kvalitātes rādītāji, Dziļās mašīnmācīšanās attēlu kvalitātes rādītāji, utt..
1.2.2. Rādītāju detalizēts apraksts un novērtējums 14
Pilnīgi noteikti šādu nodaļu nevajag, nekad nodaļās nav “X apraksts”
1.2.3. Rādītāju kvalitātes novērtējums 16
Drīzāk šeit būtu vajadzīgs rakstīt “Novērtēšanas kritēriji un rezultāti”
1.3. Attēlu kvalitātes novērtēšanas datu kopas 17
Tās nav tikai novērtēšanas datu kopas, vienkārši nosaukt Datu kopas
1.3.1. Datu kopu klasifikācija un novērtēšanas kritēriji 17
Tā nekādā gadījumā nav klasifikācija, vajag uzskaitīt kategorijas uzreiz virsrakstā Sintētiskie, zemas kvalitātes reālie, augstas kvalitātes.,,
1.3.2. Datu kopas detalizēts apraksts un novērtējums 18
Pievienot, nekādi apraksti
1.3.3. Datu kopas kvalitātes novērtējums 20
Rādītāji un novērtējums
1.4. Attēlu kvalitātes vērtējumu rādītāji pret datu kopām 23
Attēlu kvalitātes rādītāju salīdzinājums esošajos pētījumos
Metodoloģija 24 2.1. Eksperimentālā vide un tehniskā iestatīšana 25
Eksperimentālā vide un implementācija ! Jābūt github linkam
2.2. Attēlu kvalitātes novērtēšanas rādītāji 26
Atlasītie Attēlu kvalitātes novērtēšanas rādītāji
2.3. Datu kopas un apstrādes darba plūsma 28
Atlasītās datu kopas (nekāda darba plūsma)
2.4. AKN rādītāju vidējās veiktspējas vērtējumu analīzes metodoloģija
Nelietot virsrakstos saīsinājumus (ārpus metodēm un datu kopām) šausmīgi grūti saprast
Nosaukt “Salīdzināšanas protokols” un apvienot visas 2.5, 2.6, 2.7
30 2.5. Statistiskā analīze un rezultātu novērtēšana 31 2.6. Salīdzinošās analīzes metodika 31 2.7. Attēlu korelācijas analīzes metodoloģija 32
Rezultāti 33
Tik ļoti messy, ka jāpārtaisa struktūra sekojoši
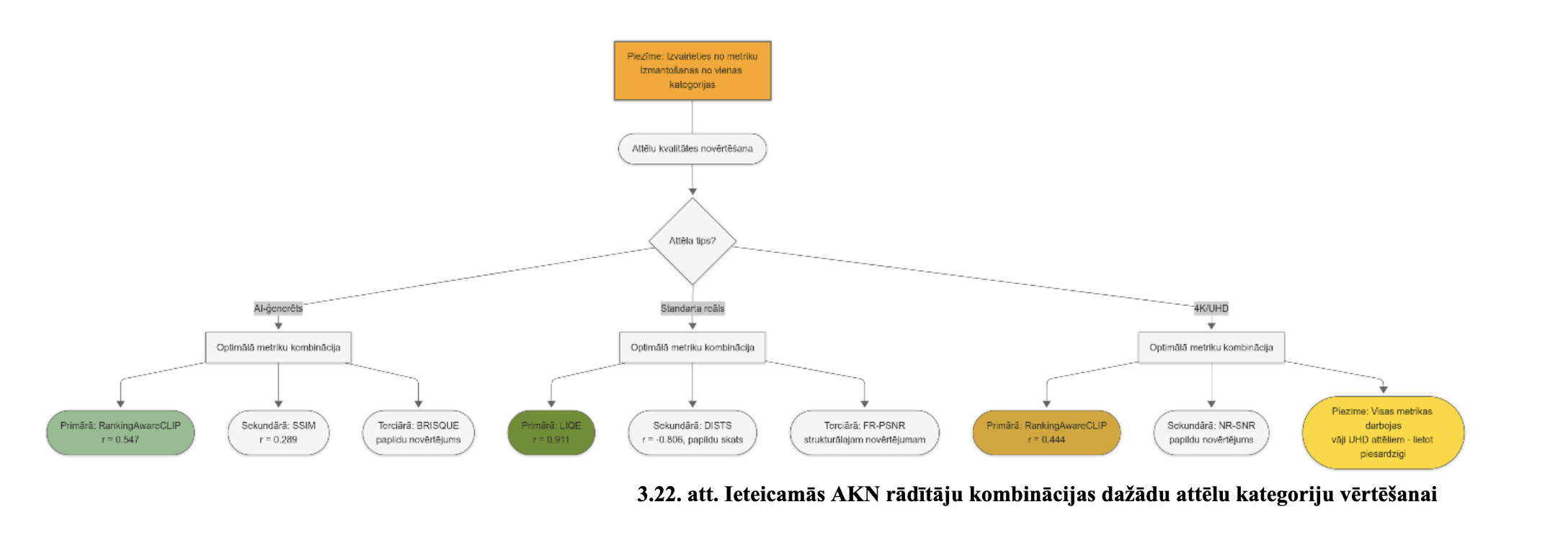
Attēlu kvalitātes rādītāju salīdzinājums katrai datu kopai
Datu kopa A
Datu kopa B
Kombinētā A, B
Visu datu kopu salīdzinājums
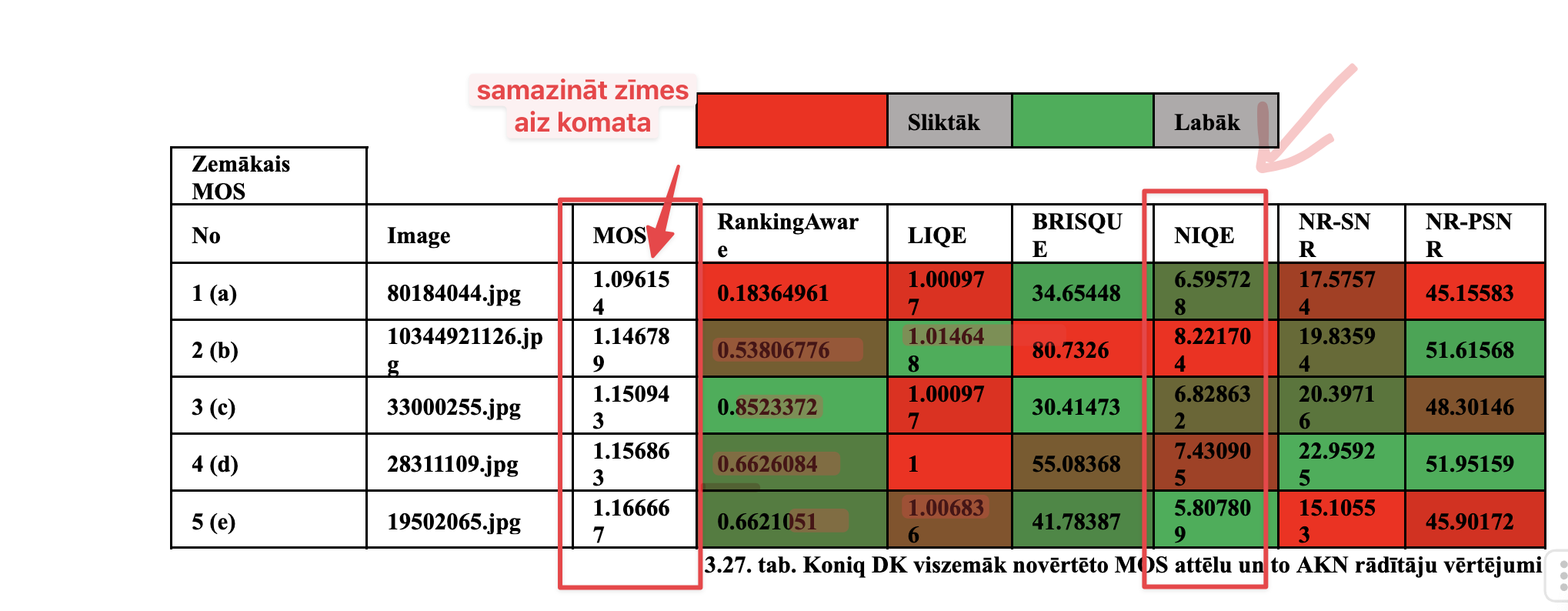
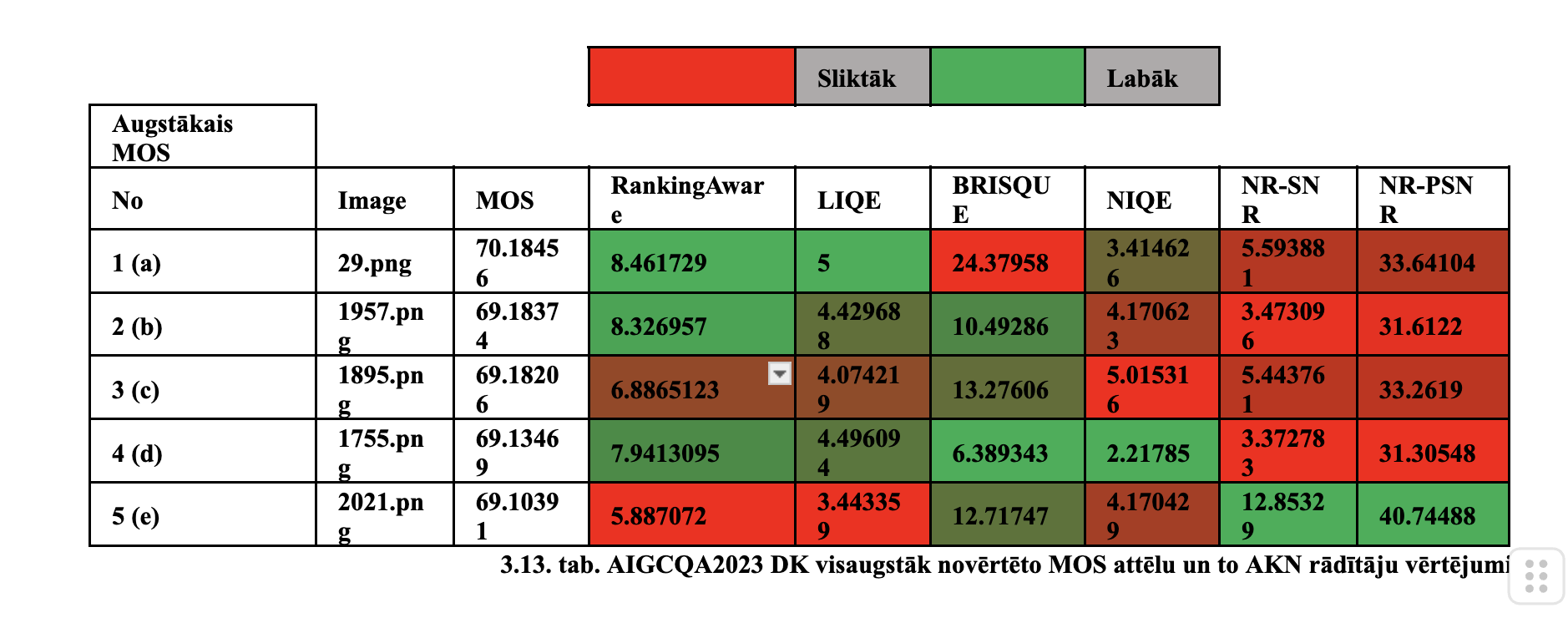
Sliktāko un labāko paraugu kvalitatīvs salīdzinājums katrai datu kopai
Datu kopa A
Datu kopa B
Kombinētā A, B
Visu datu kopu salīdzinājums
Vidējo rādītāju salīdzinājums ar apvienotām datu kopām
Kombinētā A, B
Visu datu kopu salīdzinājums (shēma)
Tālākie pētījumi 84
Secinājumi
Notes
Kuras datu kopas satur ģenerētus attēlus vai ir arī reāli attēli pret kuriem salīdzināt rezultātus?
4 real, 5 generated
Kurām datu kopām ir MOS?
Jā
Vidējo datu analīze -> just results -> Reālas vs Mākslīgajām salīdzināt
ja metodes savā starpā salīdzina uz datu kopām 9 datu punkti, vidējos MOS??? -> pearson R
salīdzināt metodes vienas datu kopas ietvaros -> spearman R (Kategorizēto rezultātu analīze pēc attēlu tipiem)
5 tuvākie <> 5 MOS tuvākie
Kura metode vislāk korelē ar MOS?
Tikai uz (ja metodes savā starpā salīdzina uz datu kopām 9 datu punkti, vidējos MOS??? -> pearson R)
Kā precīzi var izmantot metodes ar references?
.. ko tu izmanto kā references?
.. 3 datu kopas -> img-to-img
x => pieliek troksni?? => y_gen
x => text-prompt => y_gen
Source image kā reference
Deep Image Structure and Texture Similarity (DISTS)
x -> method A -> y_gen
x -> human -> y_expert
y_gen ->
metric –> score
y_expert ->
Vajag matricu, kur var redzēt rādītājus un kombinācijas ar datu kopām
Sintētiskie / Reāli
Kategorijas attēliem: foto, animācija utt Datu kopu pārklāšanās?
Vizuāli salīdzināt labos un sliktos piemērus
PSNR values of “1E+16” for identical image pairs
All CLIP-based scores were produced with ConvNeXt-large-320, but the resizing step is fixed to 512 × 512 (§2.2). You never justify this departure from the authors’ recommended 320 × 320 crop and it risks distribution shift.
^ Apmācīts uz citu uz logu nekā apmācīts
Teskta predefined pieder

No inter-rater-reliability (IRR) statistics (Krippendorff-α, Cronbach-α) are reported for the MOS labels, so one cannot judge whether the ground-truth is itself stable.

Nerādīt reizē pearson ar spearman

Statistical methods
https://github.com/NanioiNirusu/Main_metrics/blob/master/T-test_corelation.py
Parametrc vs Non-parametric tests
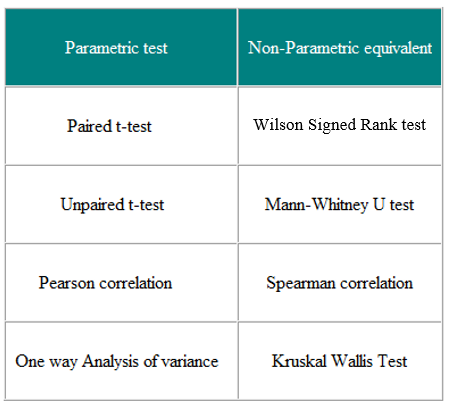
Parametric used when Gaussian distributed Non-parametric used when not Gaussian distributed
Paired test if same metric compared. Unpaired test if different scale metric used.
A quick rule of thumb
≥ 30 paired samples, differences look roughly bell-shaped → paired t-test.
Fewer samples or heavy tails/outliers → Wilcoxon signed-rank (or a permutation test).
Binary outcomes per image → McNemar’s test.
x
1from scipy import stats2stats.ttest_rel(metric_A, metric_B) # paired t-test3stats.wilcoxon(metric_A - metric_B) # Wilcoxon # unpaired
x
1from scipy.stats import mannwhitneyu2
3# unpaired 4statistic, p_value = mannwhitneyu(group1, group2, alternative='two-sided')5print(f"U statistic: {statistic}, p-value: {p_value:.4f}")
xxxxxxxxxx1from scipy.stats import wilcoxon2# unpaired3stat, p = wilcoxon(sample1, sample2)
xxxxxxxxxx1151import numpy as np2from scipy.stats import pearsonr, spearmanr3
4# Sample data5x = np.array([10, 20, 30, 40, 50])6y = np.array([12, 24, 33, 45, 58])7
8# Pearson correlation9pearson_corr, pearson_p = pearsonr(x, y)10print(f"Pearson correlation coefficient: {pearson_corr:.3f}, p-value: {pearson_p:.3e}")11
12# Spearman correlation13spearman_corr, spearman_p = spearmanr(x, y)14print(f"Spearman correlation coefficient: {spearman_corr:.3f}, p-value: {spearman_p:.3e}")15
One-way Anova
141import numpy as np2from scipy.stats import f_oneway3
4# Sample data: Exam scores for three teaching methods5method_A_scores = [85, 86, 88, 75, 78]6method_B_scores = [90, 92, 94, 89, 88]7method_C_scores = [79, 81, 83, 77, 80]8
9# Perform one-way ANOVA10f_statistic, p_value = f_oneway(method_A_scores, method_B_scores, method_C_scores)11
12print(f"F-Statistic: {f_statistic}")13print(f"P-Value: {p_value}")14
Kruskal-Wallis Test (Non-Parametric Test)
xxxxxxxxxx1131from scipy.stats import kruskal2
3# Sample data: Exam scores for three teaching methods4method_A_scores = [85, 86, 88, 75, 78]5method_B_scores = [90, 92, 94, 89, 88]6method_C_scores = [79, 81, 83, 77, 80]7
8# Perform Kruskal-Wallis test9h_statistic, p_value = kruskal(method_A_scores, method_B_scores, method_C_scores)10
11print(f"H-Statistic: {h_statistic}")12print(f"P-Value: {p_value}")13