2025-Q1-AI 14. ViT Vision Transformers - Homeworks
14.3. Implementēt modeli ar talonu mācīšanos
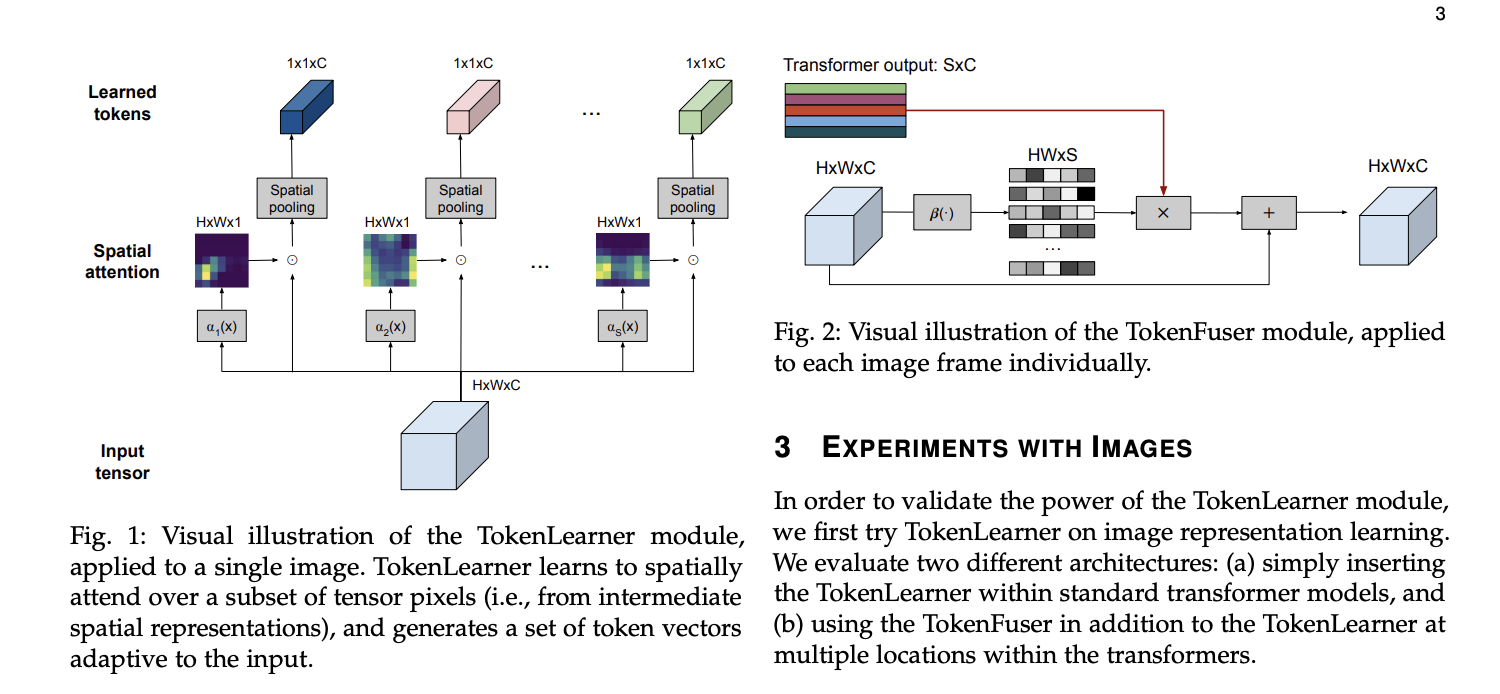
Implementēt talonu mācīšanos izmantojot 14.2 pirmkodu un pievienot “ViT Token learner” pēc publikācijas https://arxiv.org/pdf/2106.11297.pdf Paraugs pirmkodam: https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
Iesniegt pirmkodu un screenshot ar rezultātiem, salīdzināt rezultātus ar un bez “ViT Token learner”
Nepieciešamā arhitektūra
Pareizā implementācija
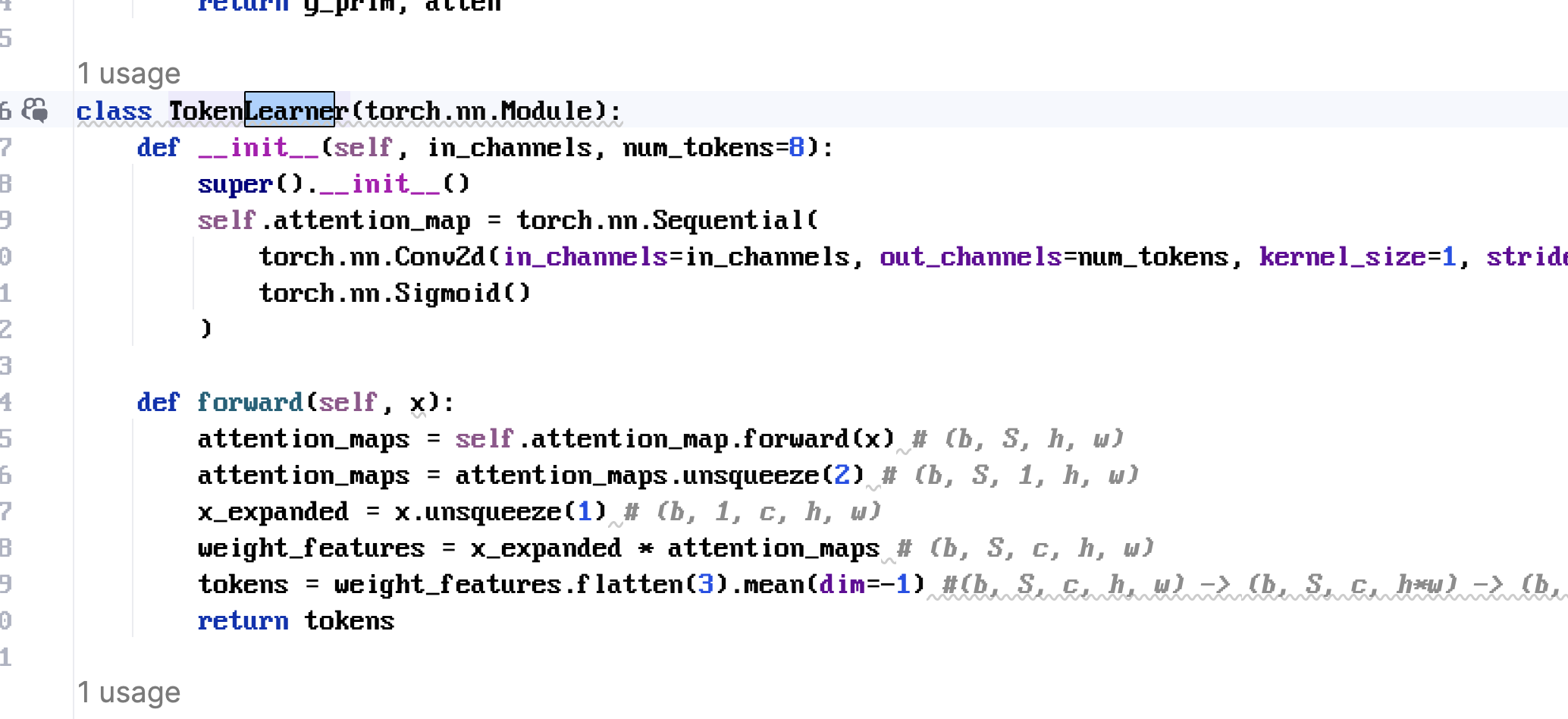
x
1import torch2import torch.nn as nn3import torch.nn.functional as F4
5class TokenLearner(nn.Module):6 """7 TokenLearner without einsum or bmm.8 Input : x — (B, C, H, W)9 Output: out — (B, S, C)10 """11 def __init__(self, in_channels: int, num_tokens: int = 8, reduction: int = 4):12 super().__init__()13 hidden = max(in_channels // reduction, 1)14 self.attn = nn.Sequential(15 nn.Conv2d(in_channels, hidden, 1),16 nn.GELU(),17 nn.Conv2d(hidden, num_tokens, 1),18 nn.Sigmoid(), # (B, S, H, W)19 )20 self.num_tokens = num_tokens21
22 def forward(self, x: torch.Tensor) -> torch.Tensor:23 B, C, H, W = x.shape24
25 # 1. Learn S spatial masks: (B, S, H, W)26 masks = self.attn(x)27
28 # 2. Broadcast-multiply each mask with the feature map29 # x_expanded : (B, 1, C, H, W)30 # masks_expanded: (B, S, 1, H, W)31 weighted = masks.unsqueeze(2) * x.unsqueeze(1) # (B, S, C, H, W)32
33 # 3. Aggregate spatially → (B, S, C)34 tokens = weighted.sum(dim=(-1, -2)) / (H * W)35 return tokens # (B, S, C)36 37 B, C, H, W = 2, 64, 32, 3238layer = TokenLearner(in_channels=C, num_tokens=8)39out = layer(torch.randn(B, C, H, W))40print(out.shape) # → torch.Size([2, 8, 64])
Acīmredzami ģenerēts kods vai arī tad, lai students izskaidro einsum funkcionalitāti kā arī kāpēc parādās softmax => atzīme 5

Nepareiza arhitektūra, bet atzīme 8, jo nav klaji ģenerēts kods

Labākais mēģinājums, kas izskatās pēc paša darba => atzīme 10