2025-05-25 Meeting 68
Nedrīkst ne anotacijā ne tekstā izcelt, ka ar uzvednēm mēs uzlabojam modeļa simbolisko spriestspēju -> mēs uzlabojam spriestspēju ar ārēju ranking vai papildus LLM.
Anotācijā pārtaisīt, lai 50%-50% ranking un mutācijas nevis tikai par mutācijām rakstīts

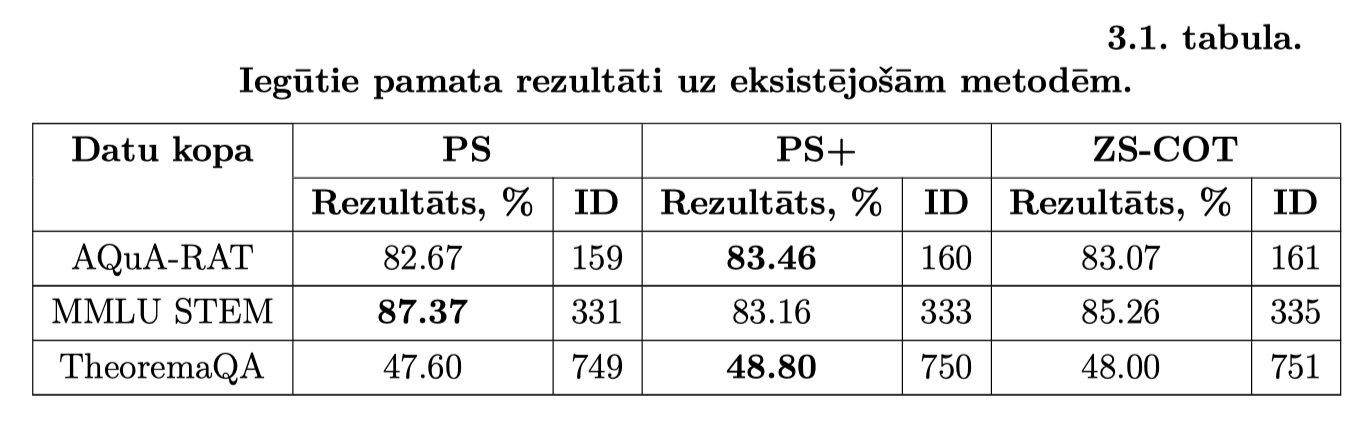
^ Neoficālie rezultāti, labākais rezultāts zintātniskā publicēts

Vai ir kaut kas kopīgs labākajiem promtps?
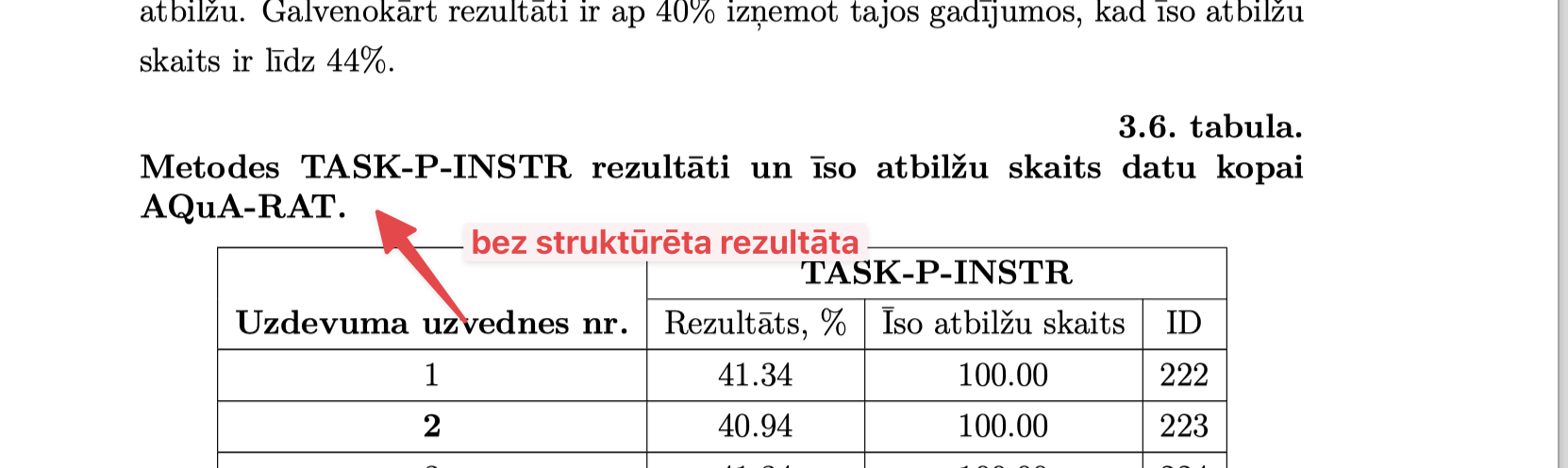
Bold


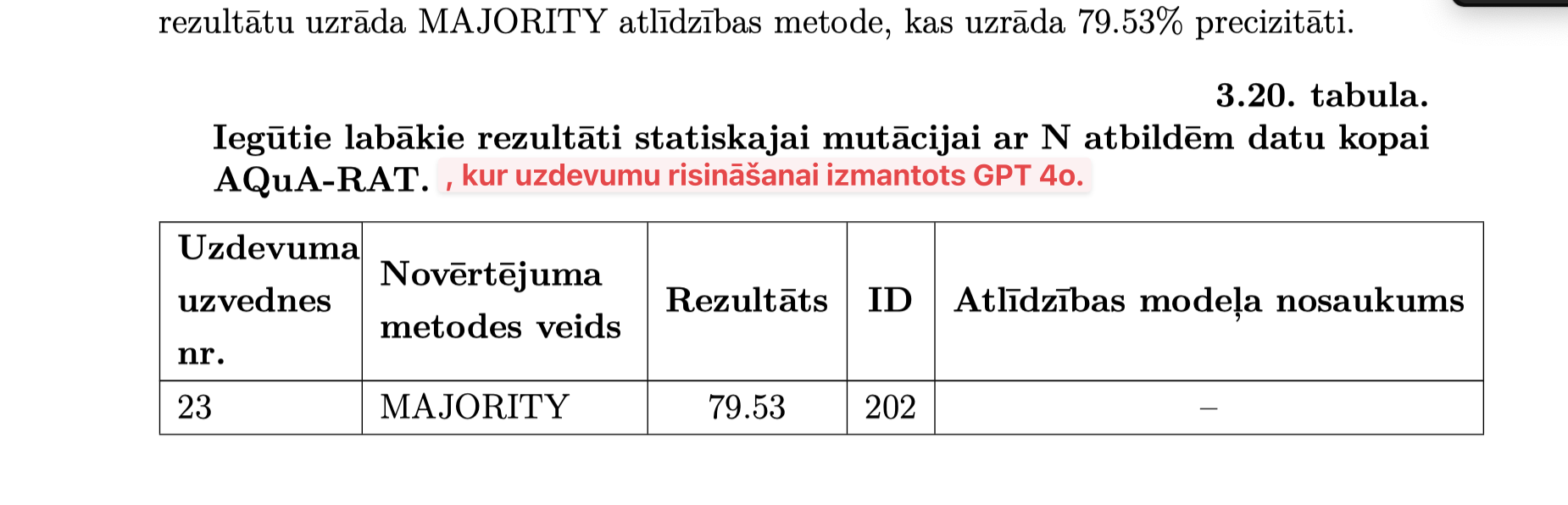
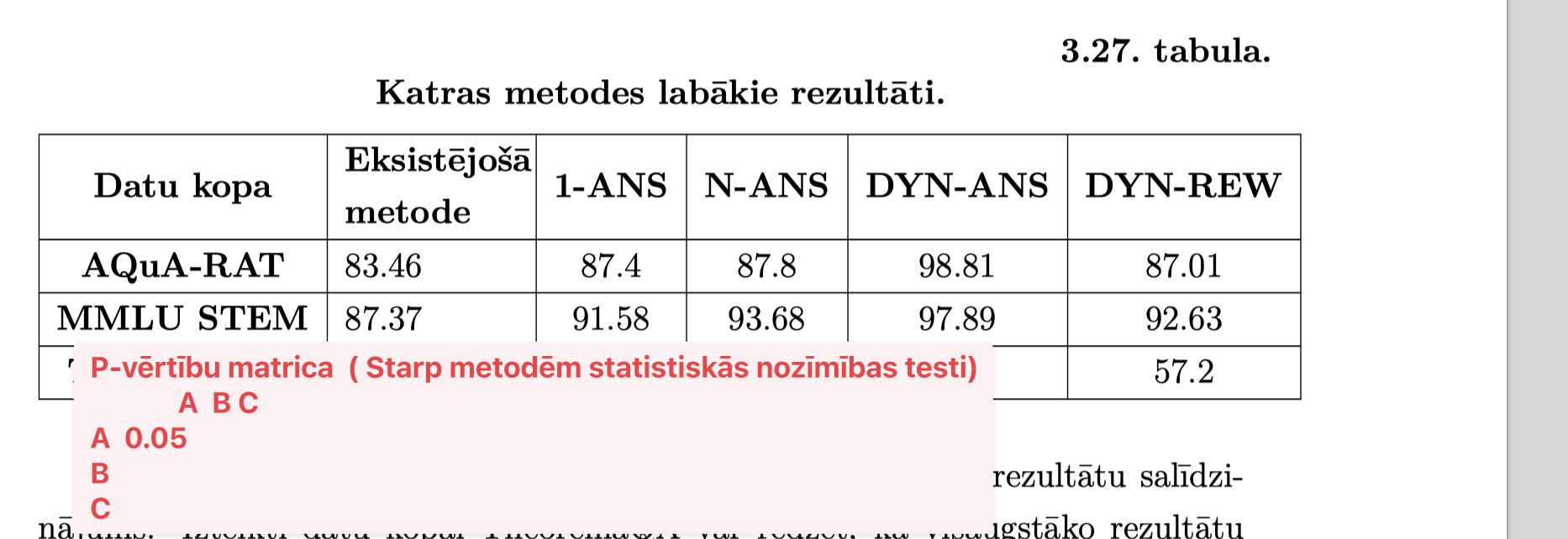
Statistiskā analīze rezultātiem
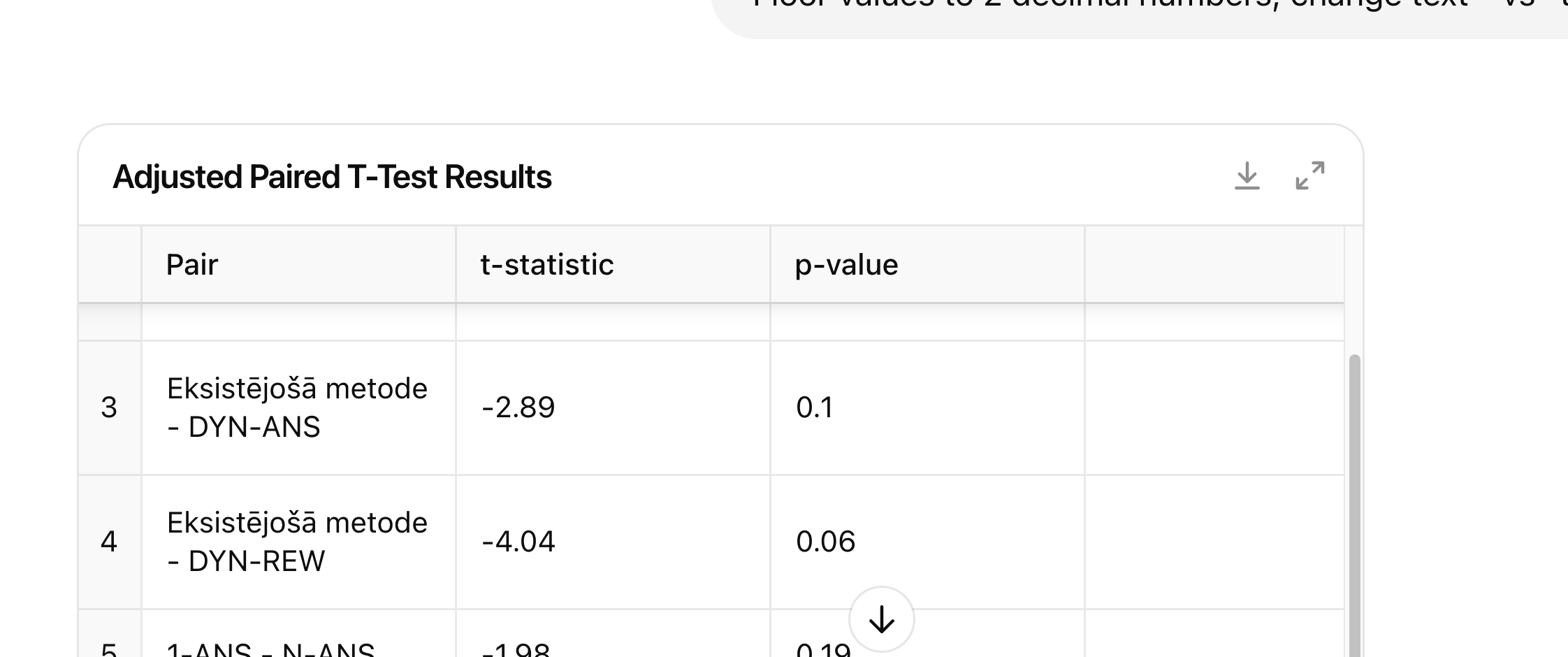
Iezīmēt pelēku DYN_ANS_GT un primāri secinājumus balstīt uz pārējām metodēm
Neizmantot vārdus ”DYN_ANS ir labākais modelis” tā vietā “kā sagaidāms augstākais rezultāts”
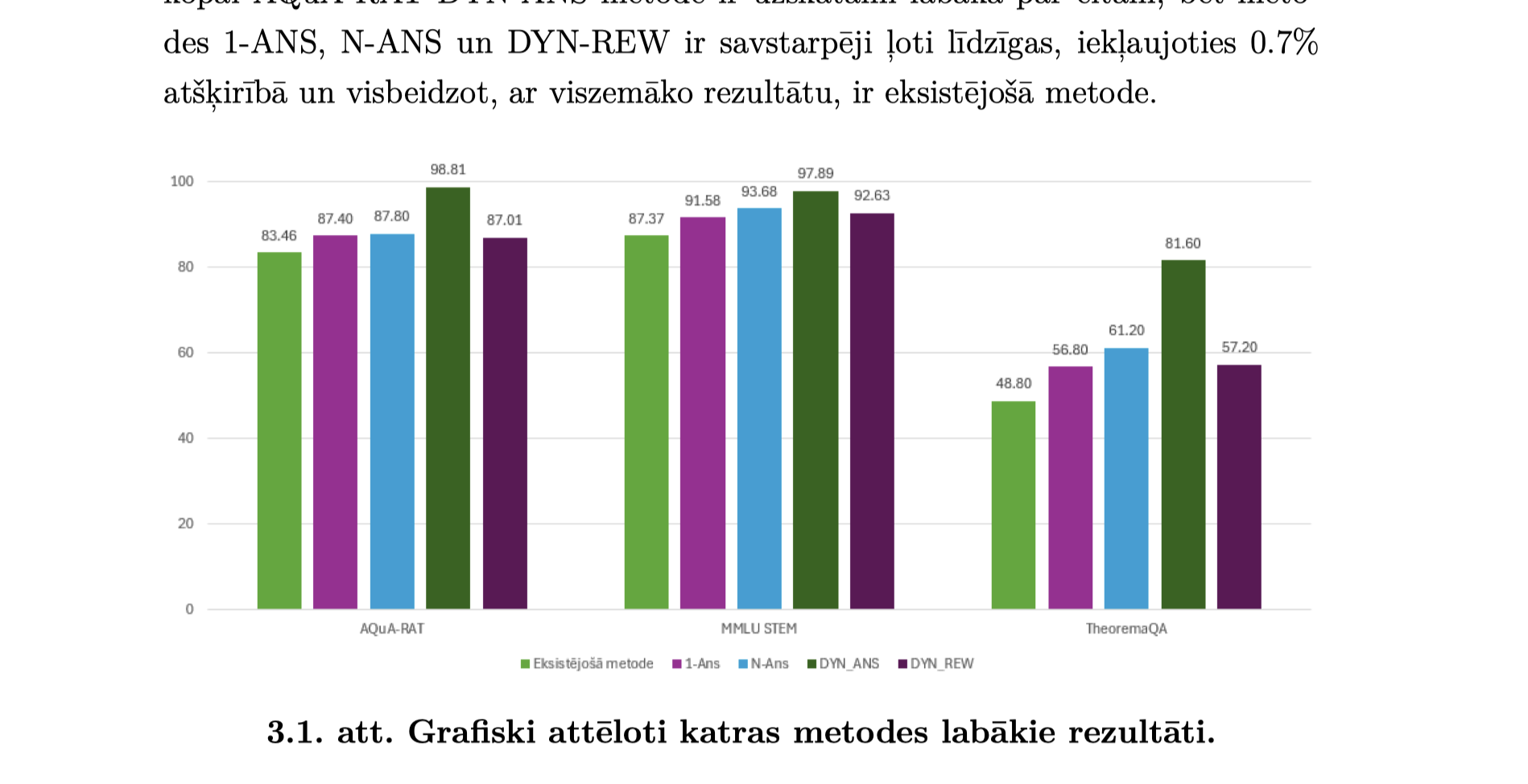
Spriešnas modeļi , bet šajā pētījumā uzsvars uz izmaksu efektīviem modeļiem un uzvedņu inženieriju nevis spriešanas modeļiem, kuri paši iteratīvi izmaina uzvednes.

Hipotēze pierādīta daļēji

Statistical methods
https://github.com/NanioiNirusu/Main_metrics/blob/master/T-test_corelation.py
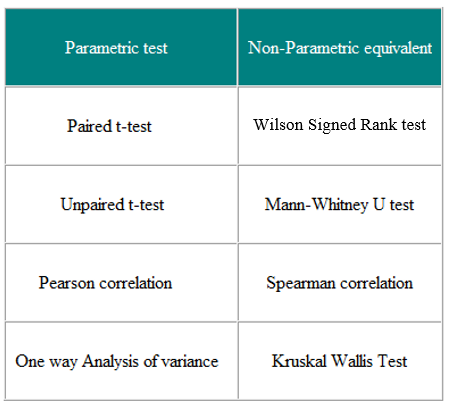
Parametrc vs Non-parametric tests
0.0 - 1.0
0.05 < satistiski nenozīmģas atšķirības
Wilson Signed Rank test
Parametric used when Gaussian distributed Non-parametric used when not Gaussian distributed
Paired test if same metric compared. Unpaired test if different scale metric used.
A quick rule of thumb
≥ 30 paired samples, differences look roughly bell-shaped → paired t-test.
Fewer samples or heavy tails/outliers → Wilcoxon signed-rank (or a permutation test).
Binary outcomes per image → McNemar’s test.
xxxxxxxxxx51from scipy import stats2stats.ttest_rel(metric_A, metric_B) # paired t-test3stats.wilcoxon(metric_A - metric_B) # Wilcoxon # unpaired
xxxxxxxxxx51from scipy.stats import mannwhitneyu2# unpaired4statistic, p_value = mannwhitneyu(group1, group2, alternative='two-sided')5print(f"U statistic: {statistic}, p-value: {p_value:.4f}")
xxxxxxxxxx31from scipy.stats import wilcoxon2# unpaired3stat, p = wilcoxon(sample1, sample2)
xxxxxxxxxx151import numpy as np2from scipy.stats import pearsonr, spearmanr3# Sample data5x = np.array([10, 20, 30, 40, 50])6y = np.array([12, 24, 33, 45, 58])7# Pearson correlation9pearson_corr, pearson_p = pearsonr(x, y)10print(f"Pearson correlation coefficient: {pearson_corr:.3f}, p-value: {pearson_p:.3e}")11# Spearman correlation13spearman_corr, spearman_p = spearmanr(x, y)14print(f"Spearman correlation coefficient: {spearman_corr:.3f}, p-value: {spearman_p:.3e}")15
One-way Anova
xxxxxxxxxx141import numpy as np2from scipy.stats import f_oneway3# Sample data: Exam scores for three teaching methods5method_A_scores = [85, 86, 88, 75, 78]6method_B_scores = [90, 92, 94, 89, 88]7method_C_scores = [79, 81, 83, 77, 80]8# Perform one-way ANOVA10f_statistic, p_value = f_oneway(method_A_scores, method_B_scores, method_C_scores)11print(f"F-Statistic: {f_statistic}")13print(f"P-Value: {p_value}")14
Kruskal-Wallis Test (Non-Parametric Test)
xxxxxxxxxx131from scipy.stats import kruskal2# Sample data: Exam scores for three teaching methods4method_A_scores = [85, 86, 88, 75, 78]5method_B_scores = [90, 92, 94, 89, 88]6method_C_scores = [79, 81, 83, 77, 80]7# Perform Kruskal-Wallis test9h_statistic, p_value = kruskal(method_A_scores, method_B_scores, method_C_scores)10print(f"H-Statistic: {h_statistic}")12print(f"P-Value: {p_value}")13
Idejas ko uzlabot
Dynamic answer mutē līdz sasniedz score
Reasoning modeļi -> pat tad, ja ar o3 būs ideāli, tad varam argumentēt, ka mūsu metode ir lietderīga pēc patērēto token skaita
xxxxxxxxxx11Provide scores for each of the answer options to the question based on your analysis. Use logical reasoning and contextual understanding to determine the most appropriate answer for the question and give that the highest score (10).
Iesaku šadu virzienu:
x1Give score for each answer to the question based on analysis. Use logical reasoning and contextual understanding to assign score 1 (worst), 2 (...), 3, 4, 5, 6, 7, 8, 9, 10 (best).
Temperatūras + N

Ranking modeļi
