2025-Q1-AI 13. Transformers, GPT
13.1. Video / Materiāli (🔴 7. maijs 18:00, Riga, Zunda krastmala 10, 122)
Zoom / Video pēc tam: https://zoom.us/j/3167417956?pwd=Q2NoNWp2a3M2Y2hRSHBKZE1Wcml4Zz09
Preparation materials: http://jalammar.github.io/illustrated-transformer/ https://arxiv.org/abs/1706.03762 (Attention is all you need) https://arxiv.org/abs/2005.14165 (Language Models are Few-Shot Learners)
Source code and materials: http://share.yellowrobot.xyz/quick/2023-12-2-3FDD4522-CC8E-46A5-9131-E753AEFB9B11.zip
Iepriekšējā gada video: https://youtu.be/z8DdZboGW6I
Saturs
Transformeriem nav atmiņa, ir tikai attention un iemācīts kā izmantot attention. Tāpēc vajag barot iekšā ļoti garu tekstu vienlaicīgi, lai nodrošinātu “atmiņu”, bet var iebarot garāku tekstu kā LSTM (max ~100 len uz LSTM, bet transformer var cik vien garu vajag)
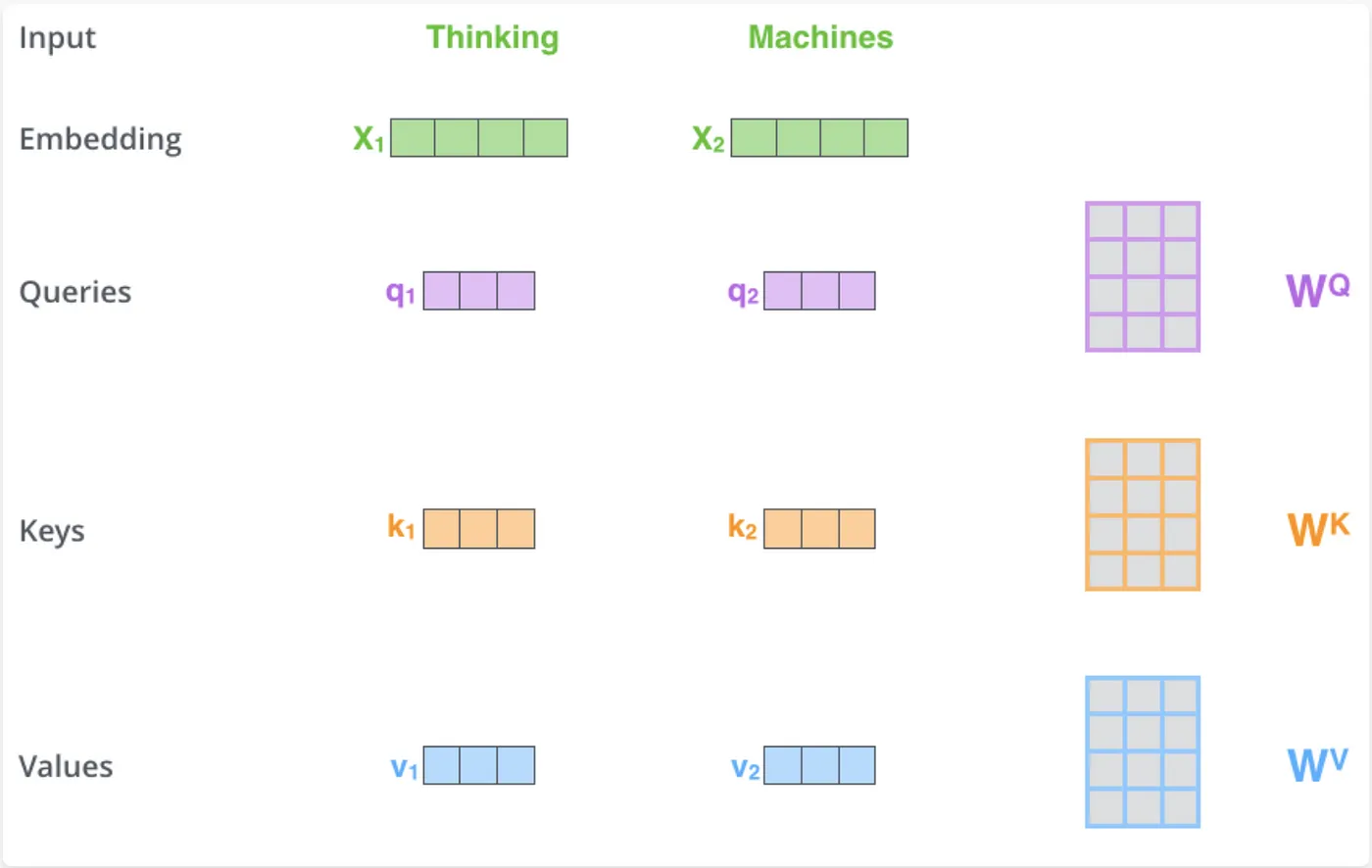
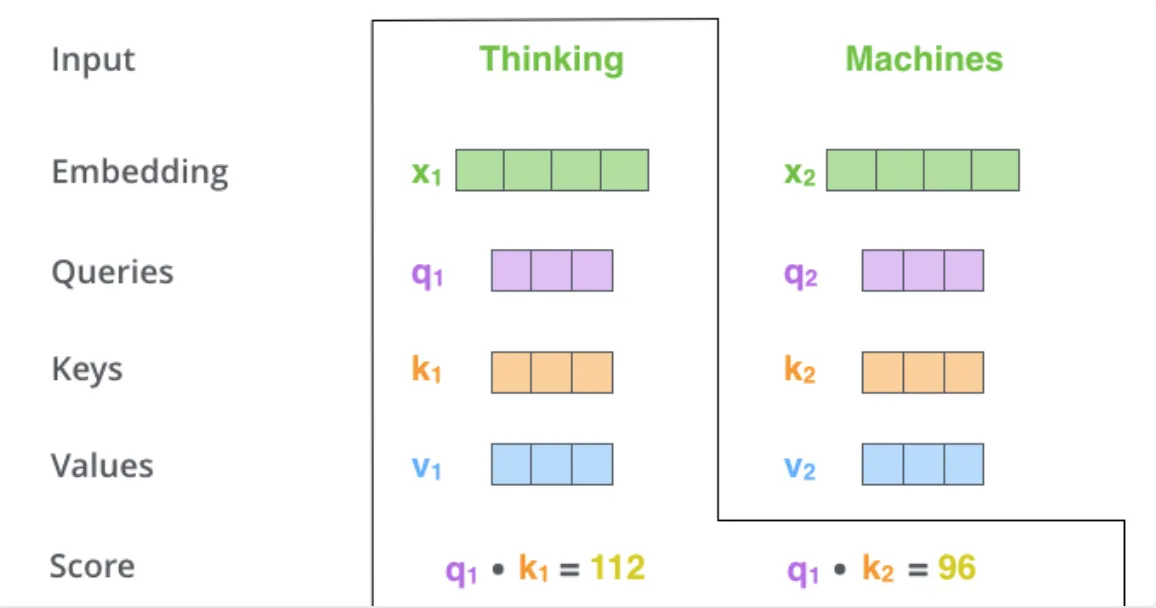
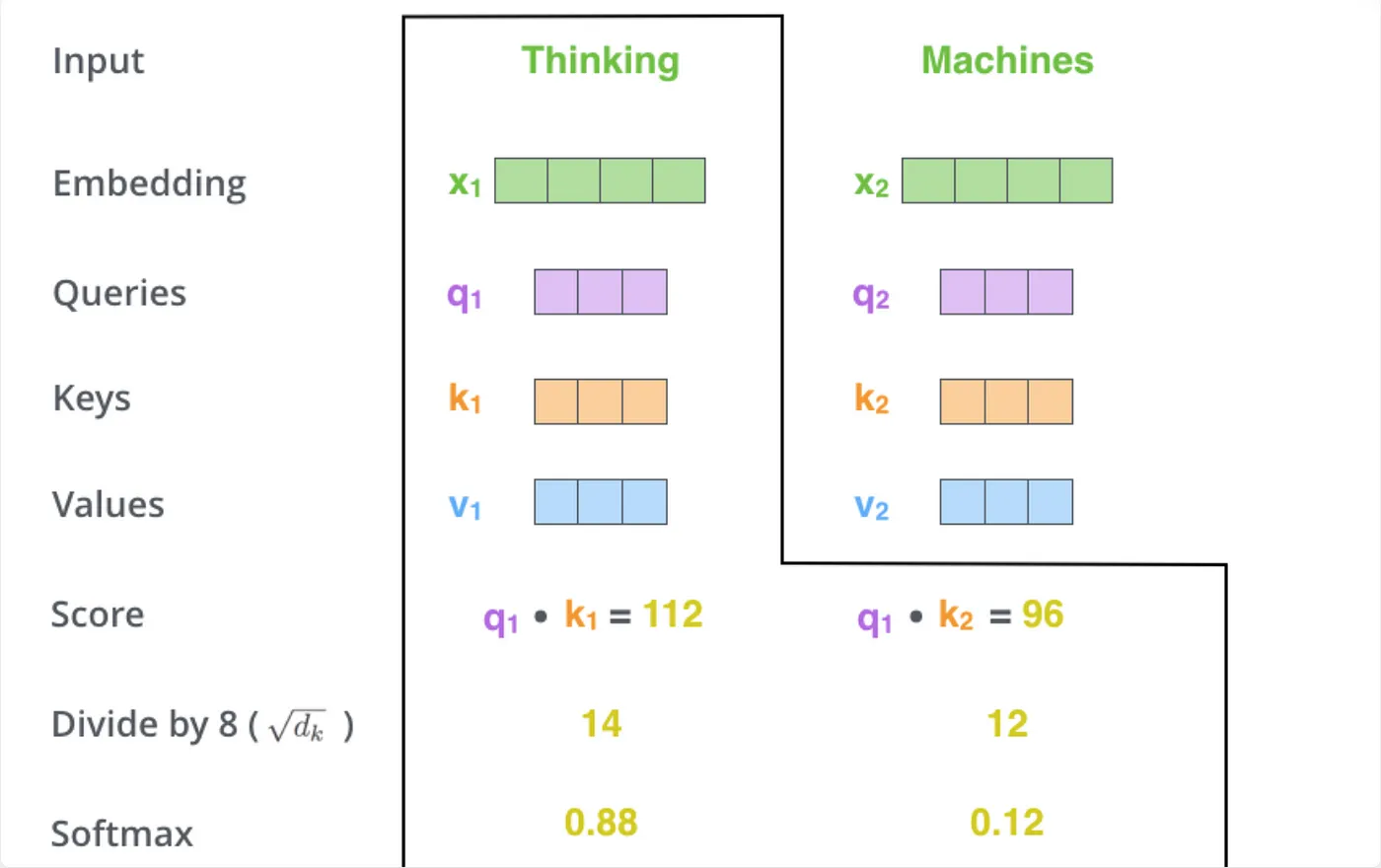
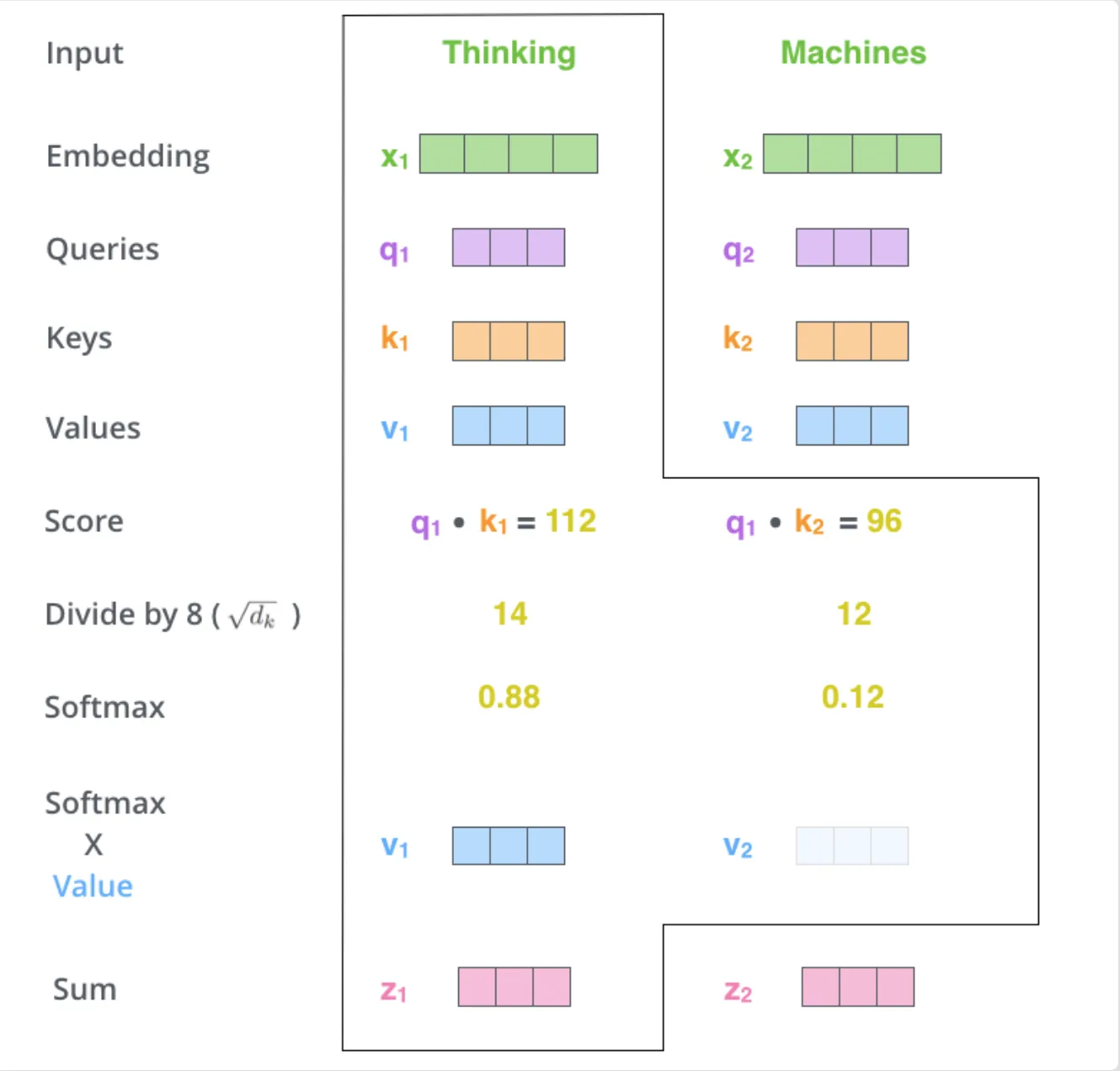
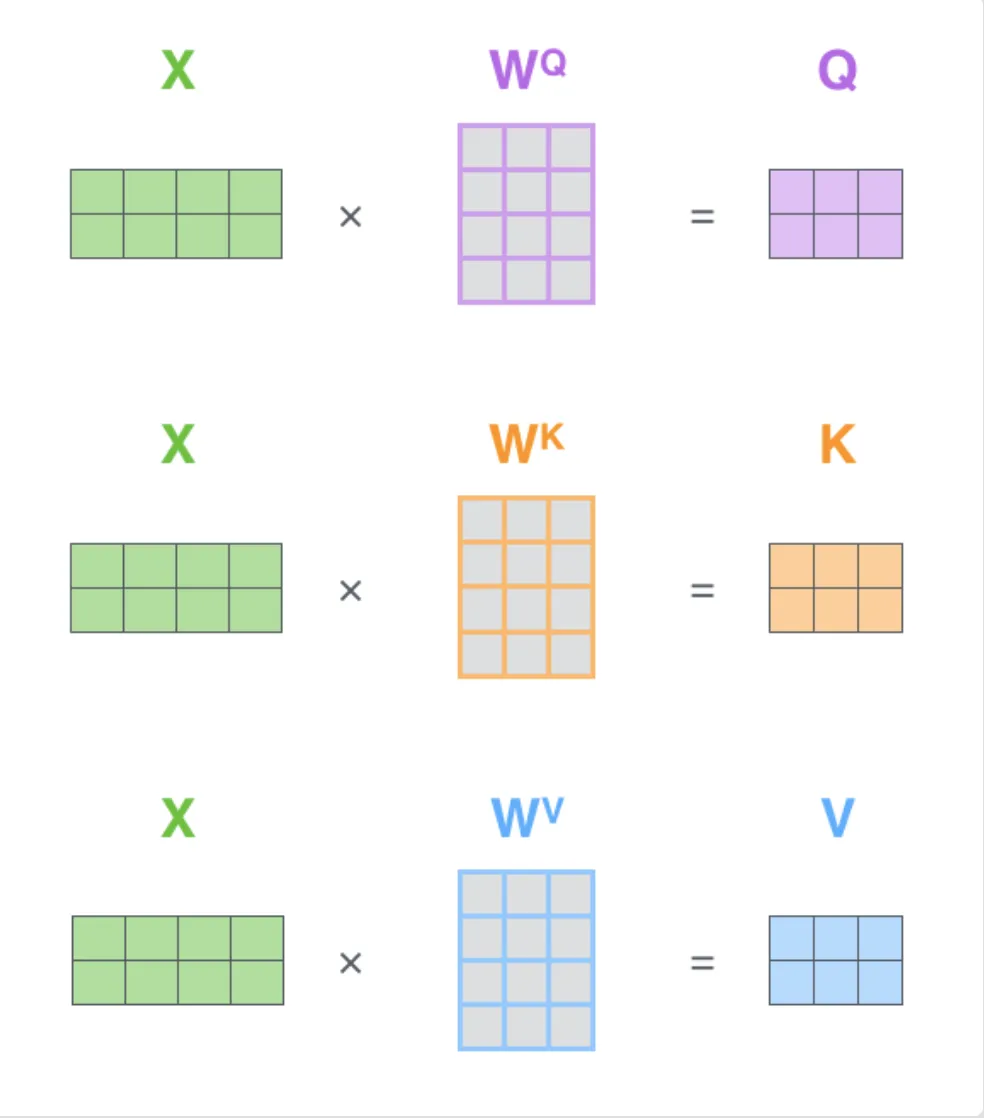
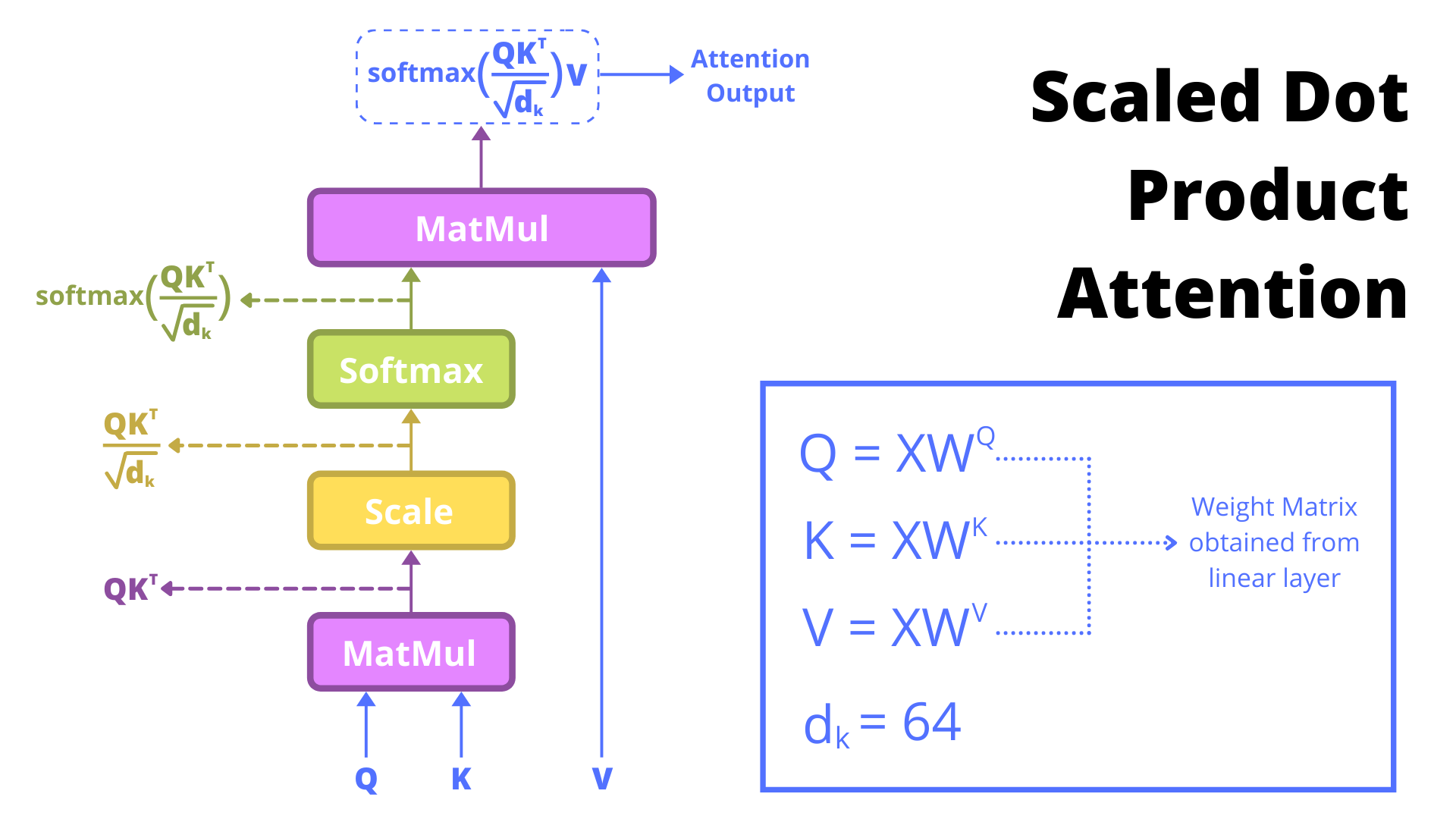
Self-attention mehānisms K, Q, V encoder var būt jebkādi MLP modeļi, galvenais ir struktūra un vienādojums, kas piespiež K, Q, V uzvesties kā paredzēts. No sākuma kodēt BEZ multihead attention - varbūt to vispār nevajag kodēt lai nav apjukums finished kodā es sakodēju jau ar multi-head.
Pastāstīt par ierobežojumiem uz tekstu garumu priekš full-attention, kurus izraisa pilns Matricas reizinājums. Tiek lietoti dažādi hacki un kombinācijas ar RNN, bet samazina precizitāti needle & haystack risinājumos. https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/
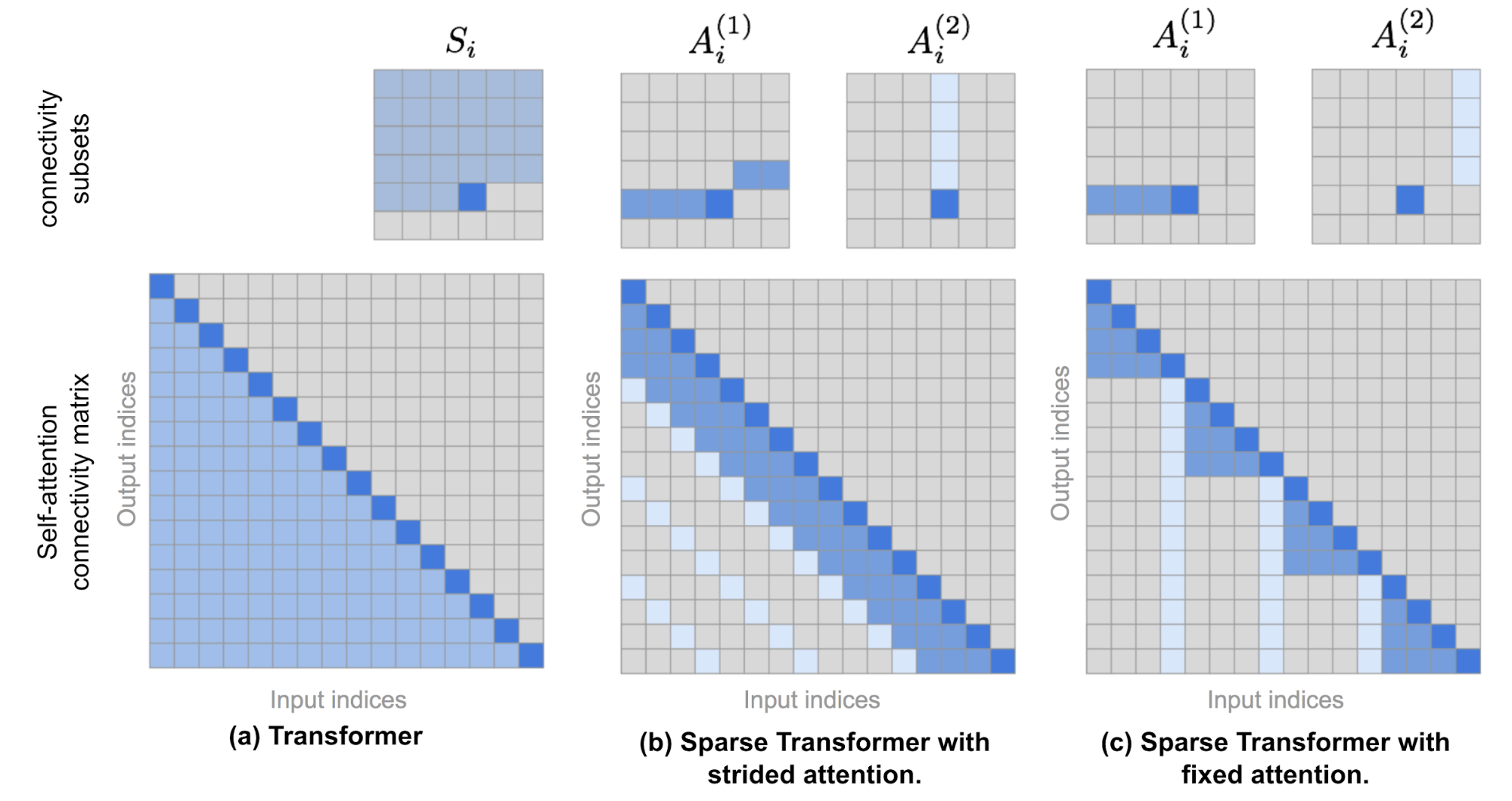
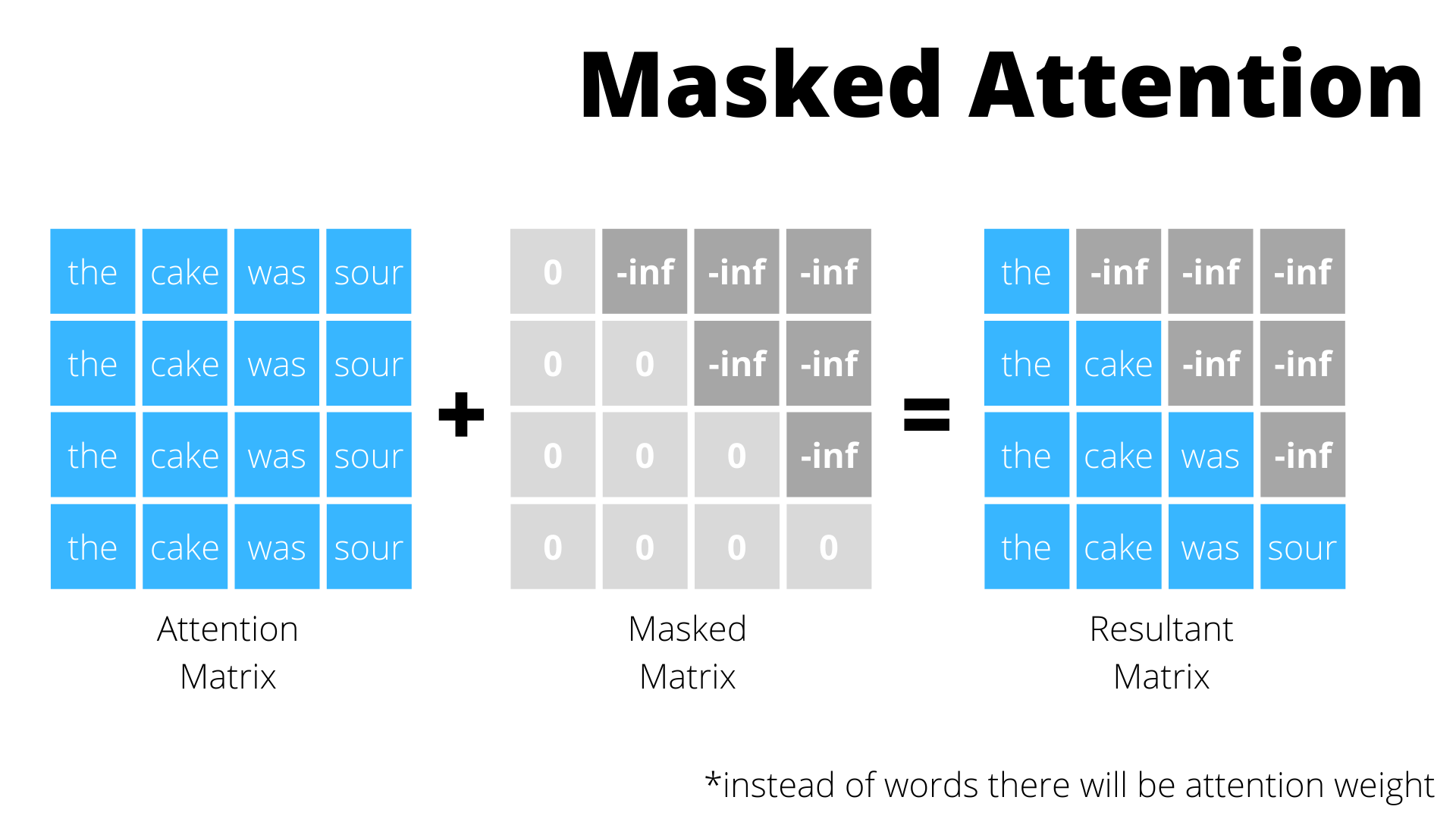
Parādīt MASK matrix, lai slēptu attention nākotni, citādi viņš ar attention nokopēs vienkārši nākotni, lai to prognozētu
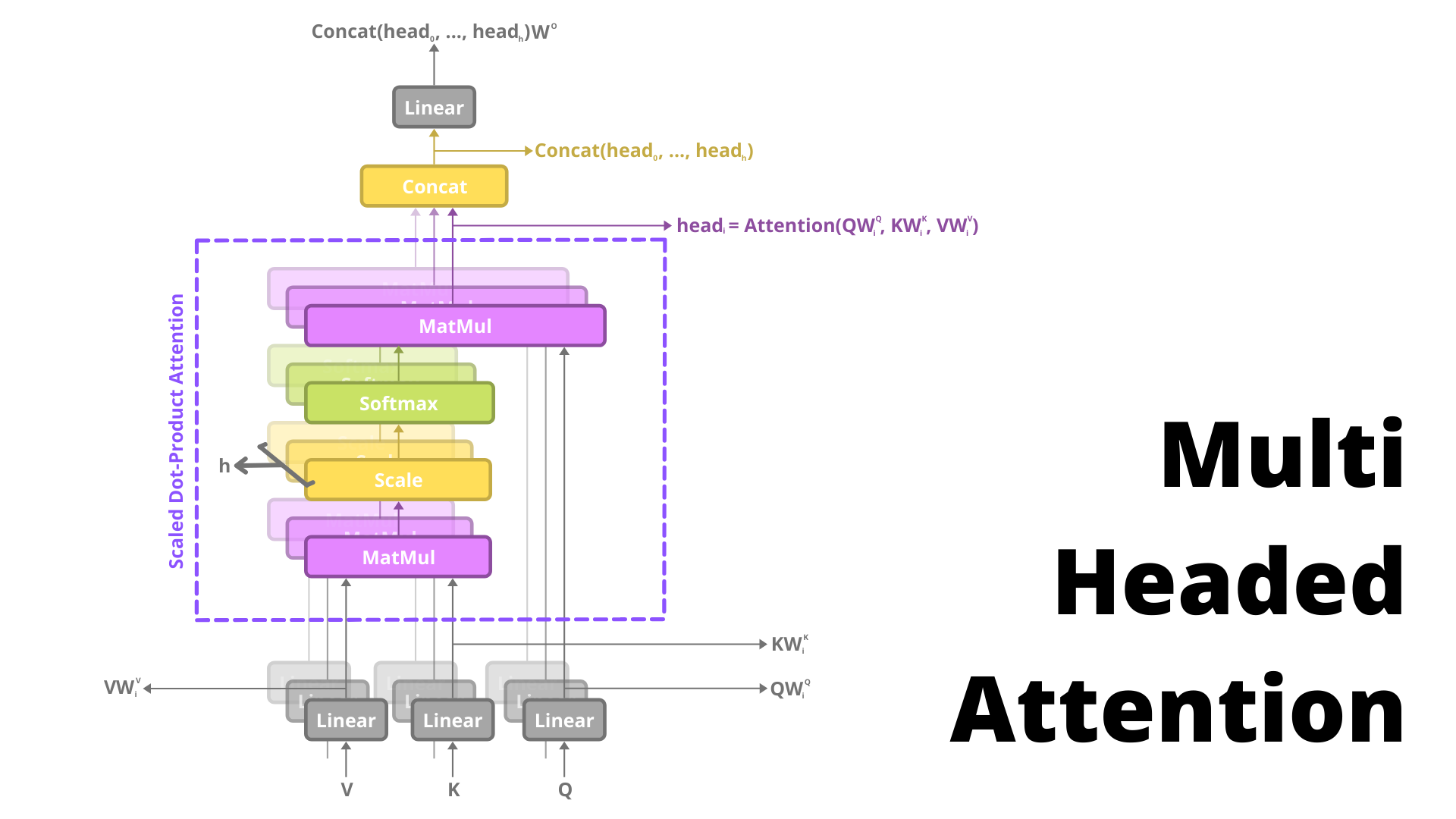
Multi-head attention - tas pats split X reizes, self-attention un beigās concat
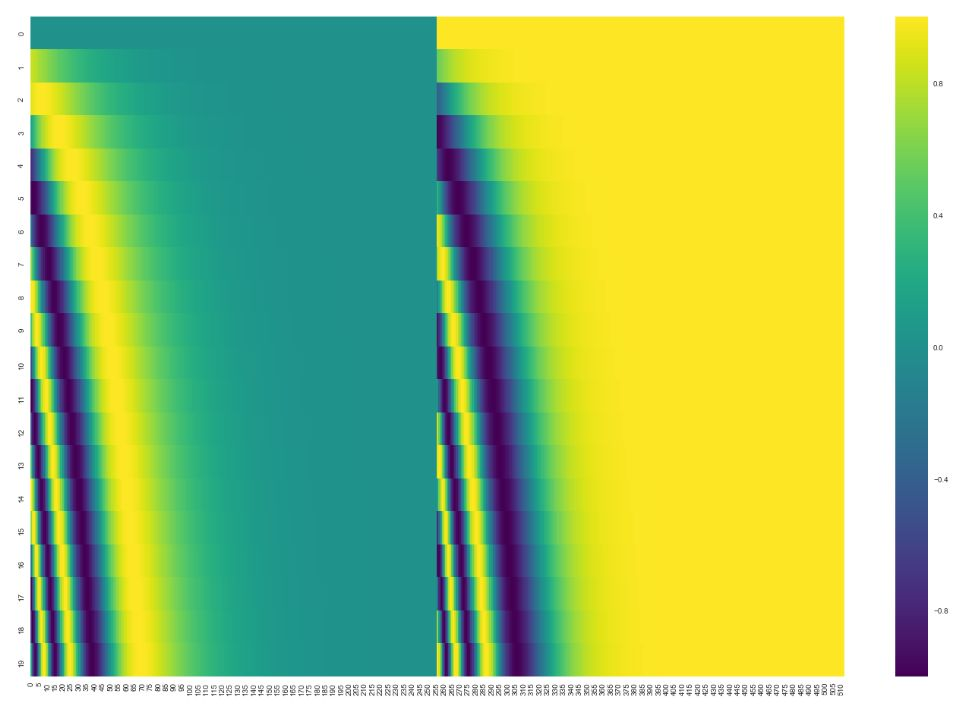
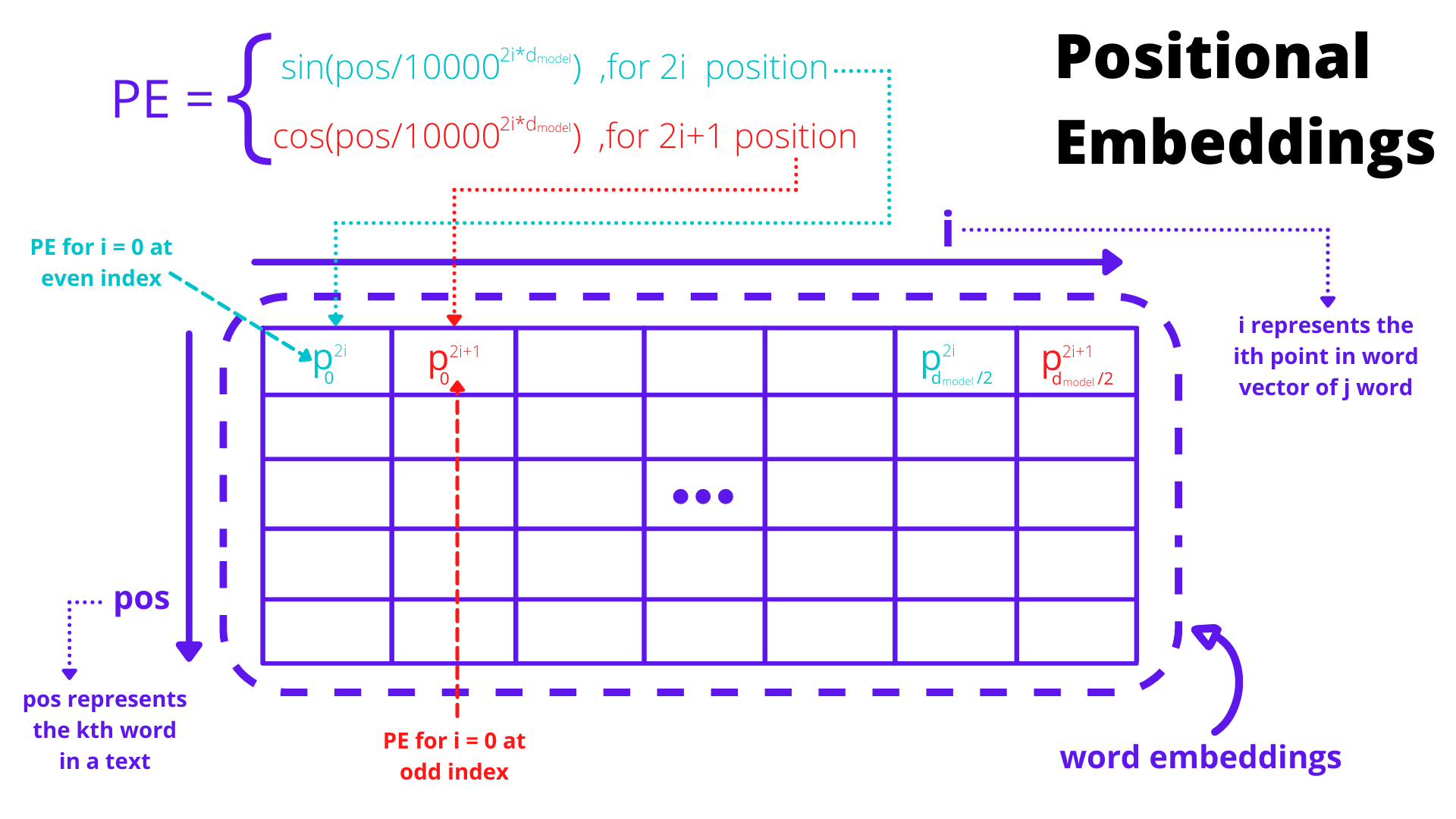
Time step embeddings - learnable vai sin-cos static
Nav starpība vai time step embeddings concat vai pieskaita līdzīgi kā UNet tas pats efekts
OpenAI GPT modeļa struktūra Word embeddings sākumā un beigās transposed word embeddings - tā pati matrica (iepriekšējā nodarbībā jau izmantojām ar LSTM)
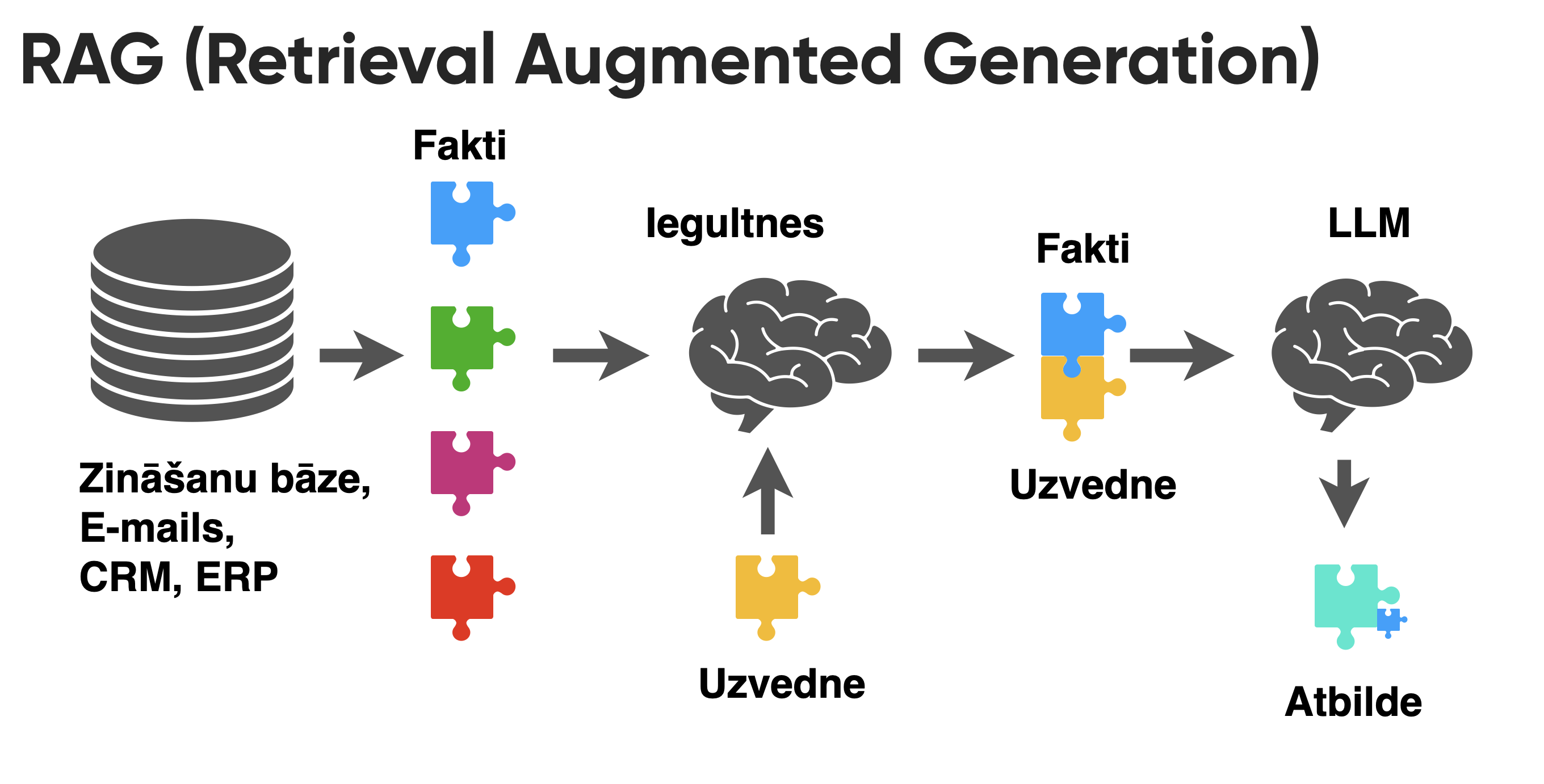
Pastāstīt beigās par RAG (Retrieval Augemented Generation), kur kopā ar text embedding modeli var izmantot pre-trained LLM un nav nepieciešams to pielāgot jeb fine-tune.
13.2. Implementēt Transformer GPT-2 modeli izmantojot instrukcijas video
Modeļa arhitektūra:
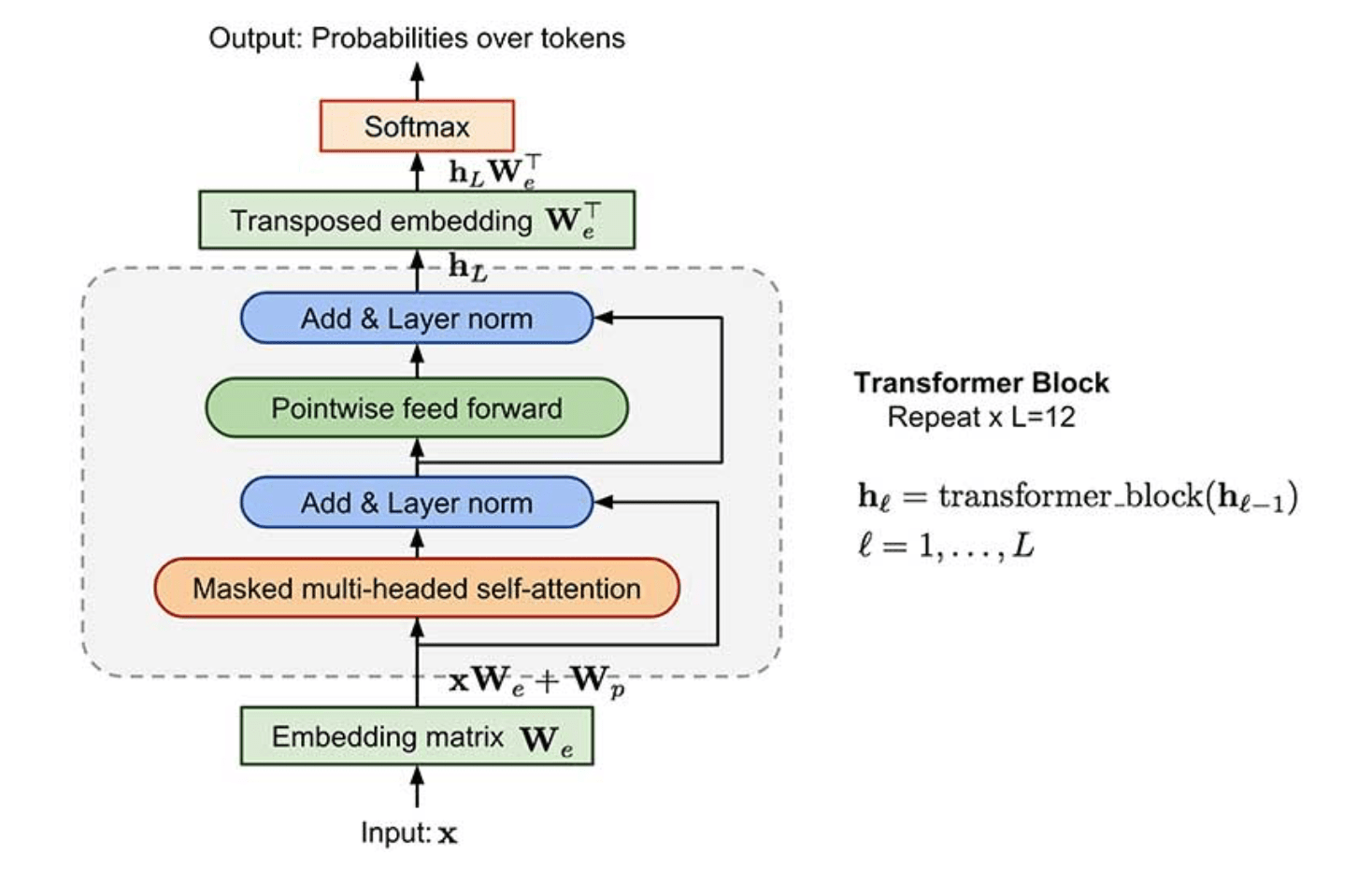
Iesniegt kodu un screenshots ar labākajiem rezultātiem.
Sagatave: http://share.yellowrobot.xyz/quick/2023-12-2-6FE0EBFB-952E-4DB4-B0E6-F72F1D3DD155.zip
13.3. Implementēt Transformer GPT-2 modeli ar multi-head attention
Multi-head attention mehānisms:
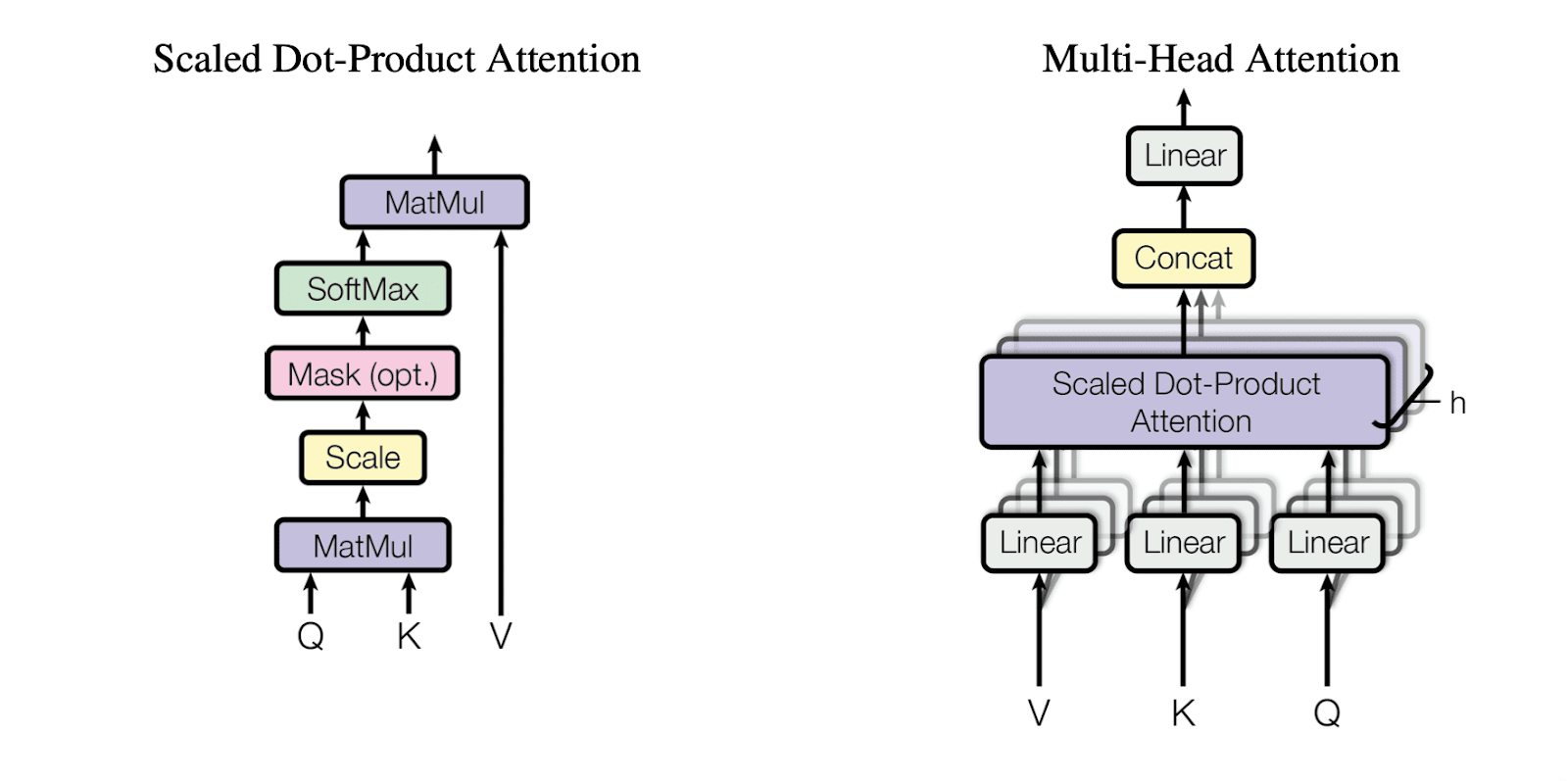
Iesniegt kodu un screenshots ar labākajiem rezultātiem.
13.4. Mājasdarbs - implementēt transformer inferenci
Implementēt TODO
Iesniegt kodu un screenshots ar labākajiem rezultātiem
Sagatave: https://share.yellowrobot.xyz/quick/2025-5-4-7E197DD7-FD52-4372-8B71-270B7AFDAB3A.zip
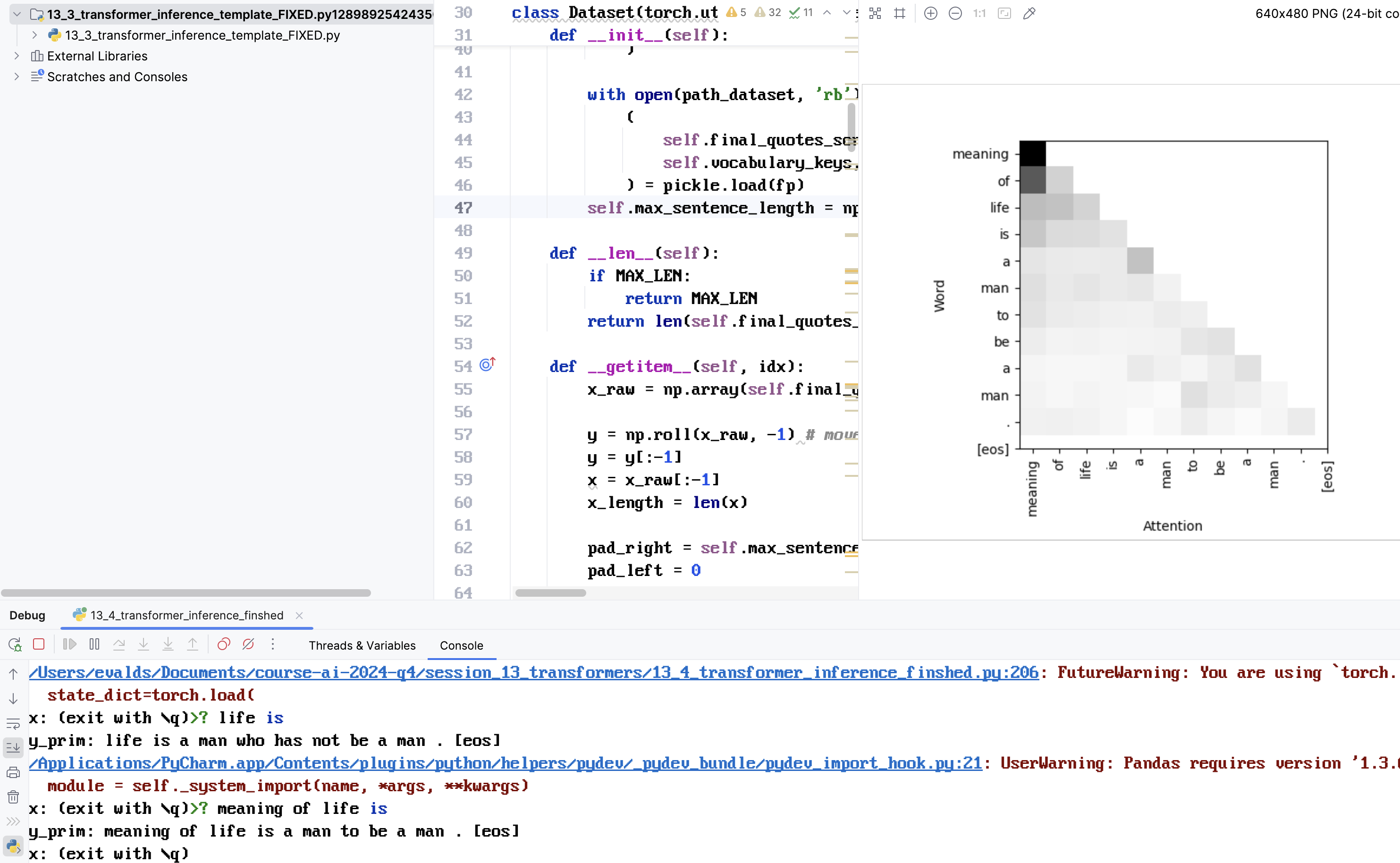
Zemāk doti piemēri no modeļa apmācības un attention matricas
Materiāli
https://medium.com/@rajrch27/a-wavelet-fractal-perspective-deciphering-transformers-f823b7c4b2e8
Uzmanības matrica tulkošanas uzdevumā bez maksas

Maskēta uzmanības matrica valodas modelēšanas uzdevuma gadījumā
Neapmācāmas pozīcijas iegultnes vai parastās Apmācāmās matricas (vai kombinācija starp abām)
🔴 Šis demonstre, ka pirmie vārdu taloni satur visvairāk informāciju LLM
https://krypticmouse.hashnode.dev/attention-is-all-you-need
https://arxiv.org/abs/2005.14165 (Language Models are Few-Shot Learners)
🔴 Īpašība, kas vēljoprojām aktuāla valodas modeļos

RAG princips