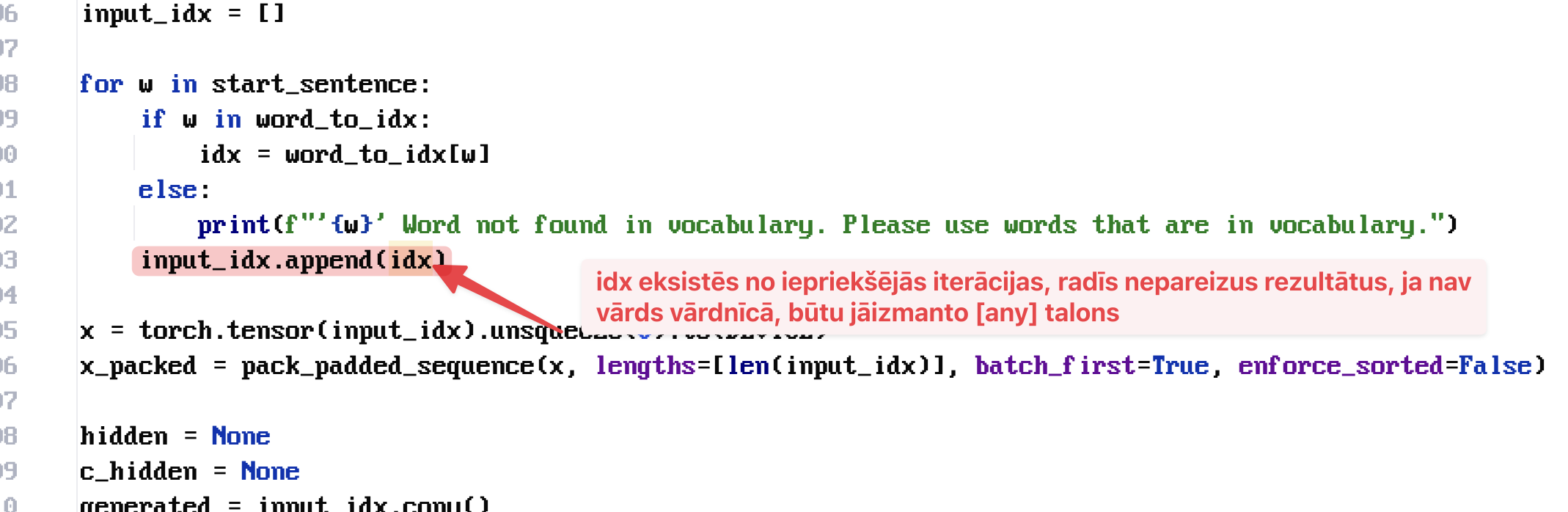
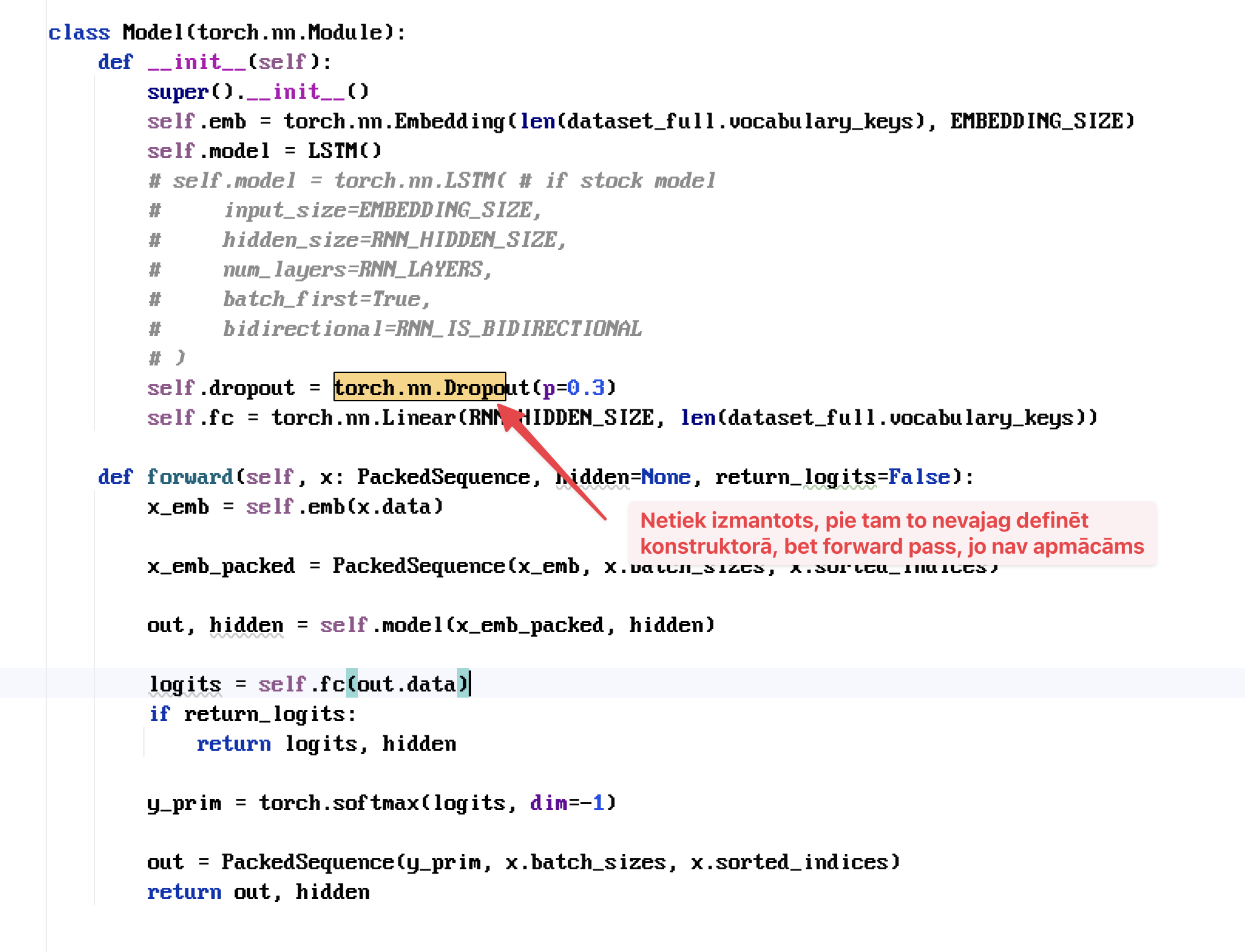
2025-Q1-AI 12. Laika rindu uzdevumi, Rekurentie neironu tīkli, RNN, LSTM - Majasdarbi
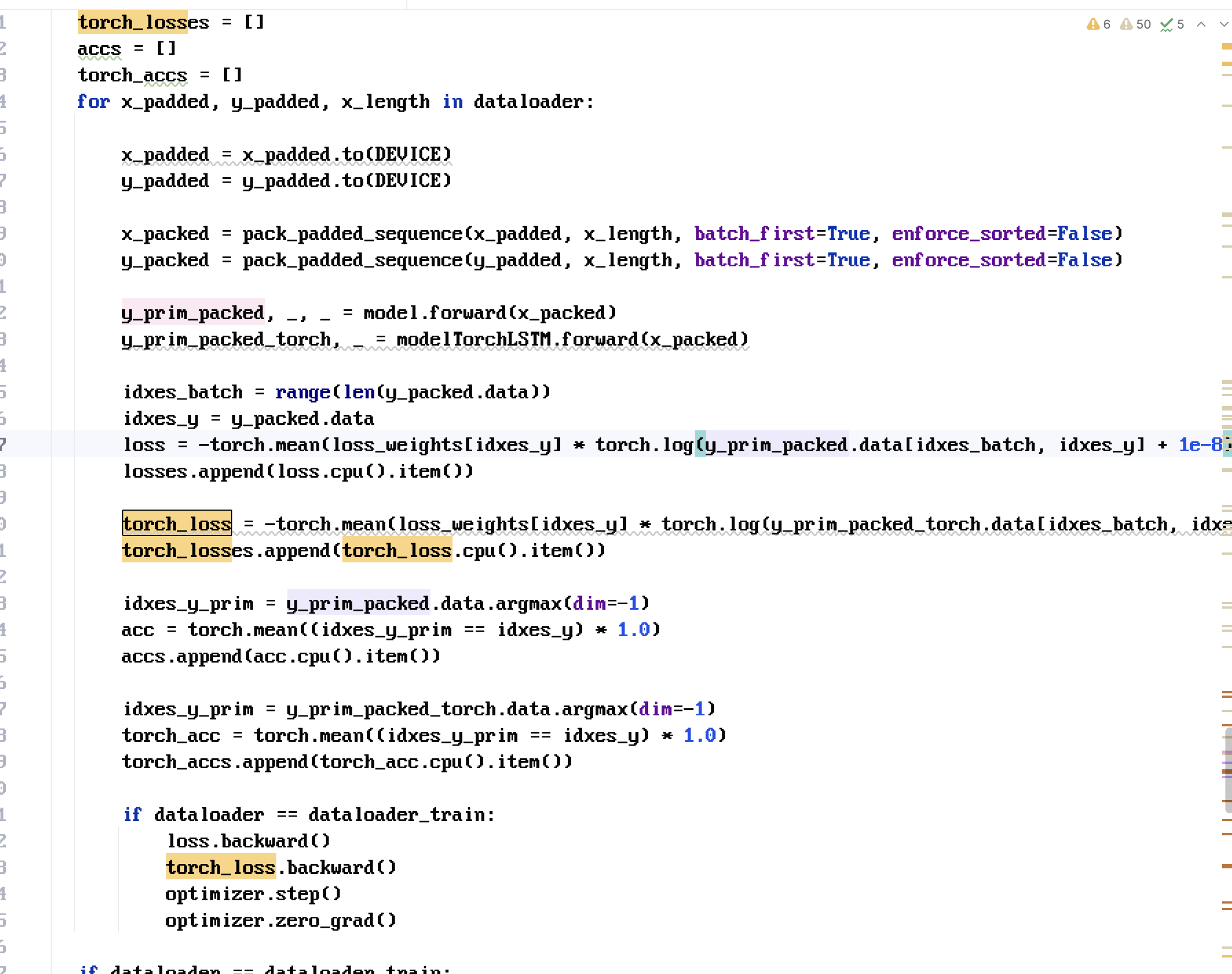
Labs mēģinājums, bet modeļus nekad neapmāca vienlaicīgi vienā apmācību ciklā, pareizi ir apmācīt atsevišķi, ko var darīt arī paralēli! Liels potenciāls kļūdām, gradienta noplūdēm kā arī katrs modelis koverģēs savā laikā!
Nepareizi implementēts output gate vienādojums:
python o_t = torch.tanh(W_o_dot_x + U_o_dot_h + self.b_o)
Jābūt sigmoid funkcijai (σ), nevis tanh:
python o_t = torch.sigmoid(W_o_dot_x + U_o_dot_h + self.b_o)